

Andy-H
-
Posts
2,000 -
Joined
-
Last visited
-
Days Won
1
Posts posted by Andy-H
-
-
Oh, sorry, I just mean I only want to use things pre-packaged with PHP, like available on servers where PHP was built with default configuration.
-
I was looking at that yesterday, I'd rather do it using SPL if possible, as I might re-use this code in several environments.
-
OK, I now have:
Template.class.php
<?php namespace phantom\classes\templating; class Template { protected $_document; public function __construct($tmpl_file, array $data = array(), $ver = '4.01', $enc = 'UTF-8') { $this->_document = new DOMDocument($ver, $enc); $this->_document->loadHTML($this->_getContent($tmpl_file, $data)); } public function getContent($file_name, array $data = array()) { return new Content($this->_getContent($file_name, $data), $this->_document); } protected function _getContent($file_name, array $data = array()) { ob_start(); extract($data, EXTR_SKIP); include 'templates'. DIRECTORY_SEPARATOR . $file_name .'.tmpl.php'; return ob_get_clean(); } }Content.class.php
<?php namespace phantom\classes\templating; class Content { protected $_content; protected $_document; public function __construct($content, DOMDocument $document) { $this->_content = $content; $this->_document = $document; } public function insertBefore($tag) { $this->_getElement($tag); } public function insertAfter($tag) { } public function appendTo($tag) { } public function prependTo($tag) { } protected function _getElement($tag) { if ( substr($tag, 0, 1) == '#' ) return $this->_document->getElementById(substr($tag, 1)); } }I am now stuck as to how to convert a HTML string into a document fragment, I know you can do this with well-formed XHTML, however, I am using HTML 4.01, anyone got any ideas how I could do something along the lines of:
$DOMDocument->loadFragment('<div class="slider"><h1>Tracking vehichles</h1><p>Blah blah blah</p><>')->insertAfter(DOMNode);?? thanks for any help.
-
If your wanting to parse HTML you should use DOMDocument. Your HTML will have to be mostly valid though for it to work properly. Parsing HTML with regex is generally considered a bad idea. It works sometimes, I'll do it sometimes for one-off re-format scripts or small personal-use scrapers but for something like a template engine you'd be better off going with a real html parsing solution like domdocument.
Ok, so scrap the regex idea, thanks.
I also have another problem, I want to be able to call templates like so:
$Page = (new Template('default', ['site' => 'b2c']))->getContent('slider')->insertAfter('#header');However, after calling getContent, I want it to return another object for the insertAfter, rather than update a class member to hold the content, this way the insertBefore/after / append/prependTo methods are only exposed when content is loaded, is this the right way to go?
Here's what I have so far.
Template.class.php
namespace phantom\classes\templating; class Template { protected $_pageContent; public function __construct($template, array $data = array()) { $this->_pageContent = $this->_getContent($template, $data); } public function getContent($file_name, array $data = array()) { return new Content($this->_getContent($file_name, $data), $this); } public function querySelector($selector) { $selector = expolode('#', $selector); $tag = $selector[0]; $match = $selector[1]; } protected function _getContent($file_name, array $data = array()) { ob_start(); extract($data, EXTR_SKIP); include 'templates'. DIRECTORY_SEPARATOR . $file_name .'.tmpl.php'; return ob_get_clean(); } }Content.class.php
namespace phantom\classes\templating; class Content { protected $_content; protected $_template; public function __construct($content, Template $tmpl) { $this->_content = $content; $this->_template = $tmpl; } public function insertBefore($tag) { } public function insertAfter($tag) { } public function appendTo($tag) { } public function prependTo($tag) { } }But now I am unsure of how to update the template contents without exposing public methods to set the content??
-
Now got
$tag = 'span'; $pat = <<<PAT ~(.*)(<{$tag}.*class\s*=\s*["?|'?]testing["?|'?][^>]*>)(.*?)(</\s*{$tag}\s*>)(.*)~is PAT; $htm = <<<HTM <span> <span class="testing" id="test">Test</span> <span class="testing" id="testing">Testing</span> </span> HTM; preg_match_all($pat, $htm, $matches, PREG_SET_ORDER); echo '<pre>'. htmlentities(print_r($matches, 1));Outputs:
Array ( [0] => Array ( [0] => <span> <span class="testing" id="test">Test</span> <span class="testing" id="testing">Testing</span> </span> [1] => <span> <span class="testing" id="test">Test</span> [2] => <span class="testing" id="testing"> [3] => Testing [4] => </span> [5] => </span> ) )
Desired output:
Array ( [0] => Array ( [0] => <span> <span class="testing" id="test">Test</span> <span class="testing" id="testing">Testing</span> </span> [1] => <span> [2] => <span class="testing" id="test"> [3] => Test [4] => </span> [5] => <span class="testing" id="testing">Testing</span> </span> ) [1] => Array ( [0] => <span> <span class="testing" id="test">Test</span> <span class="testing" id="testing">Testing</span> </span> [1] => <span> <span class="testing" id="test">Test</span> [2] => <span class="testing" id="testing"> [3] => Testing [4] => </span> [5] => </span> ) )
-
I am writing a simple templating system for a website I'm making, basically I want to retrieve content from files and insert it into a document using jquery style selectors, I'm unsure whether to use DOMDocument or regular expressions, which one would be faster for this? I'm leaning for regex atm but I'm not too clued up on it:
<?php $tag = 'span'; $pat = <<<PAT ~(.*?)<{$tag}.*id\s*=\s*["?|'?]testing["?|'?][^>]*>(.*?)</\s*{$tag}\s*>|\s*>|\s*/>(.*?)~i PAT; $htm = <<<HTM test <span id="test">Test</span> <span class="testing" id="testing">Testing</span> tredst HTM; preg_match_all($pat, $htm, $matches); echo '<pre>'. htmlentities(print_r($matches, 1), ENT_QUOTES, 'UTF-8'); ?>OUTPUT:
Array ( [0] => Array ( [0] => > [1] => > [2] => <span class="testing" id="testing">Testing</span> ) [1] => Array ( [0] => [1] => [2] => ) [2] => Array ( [0] => [1] => [2] => Testing ) [3] => Array ( [0] => [1] => [2] => ) )
Desired:
Array ( [0] => Array ( [0] => test <span id="test">Test</span> [1] => <span class="testing" id="testing"> [2] => Testing [3] => </span> tredst ) )
Any help appreciated.
P.S. Sorry if this should be in regex help, I was unsure as I also wanted advice on whether it was the right decision not to go with DOMDocument.
-
Yep, Google's algorithm is far too advanced to get away with that.
You could create a script that outputs JSON, then use it in PHP and jQuery:
<?php // SuccessException.class.php class SuccessException extends Exception { protected $_data; public function __construct($message, array $data, $code = 0, Exception $previous = NULL ) { $this->_data = $data; } public function getData() { return $this->_data; } } ?><?php // get_vehicle.php include 'SuccessException.class.php'; try { if ( !isset($_GET['vehicle_ID']) ) throw new Exception('No vehicle ID supplied'); // include 'database.const.php'; $dbh = new PDO('mysql:dbname='. DB .';host='. DB_HOST, DB_USER, DB_PASS); $dbh->setAttribute(PDO::MYSQL_ATTR_INIT_COMMAND, "SET NAMES 'UTF8'"); $dbh->setAttribute(PDO::ATTR_EMULATE_PREPARES, true); $stmt = $dbh->prepare('SELECT make, model, registration, description, price FROM vehicles WHERE vehicle_ID = ? LIMIT 1'); $stmt->bindParam(1, $_GET['vehicle_ID'], PDO::PARAM_INT); if ( $stmt->execute() === false ) throw new Exception('An unknown error has occured'); $row = $stmt->fetch(PDO::FETCH_ASSOC); if ( !count($row) ) throw new Exception('No vehicle with that ID'); throw new SuccessException('', $row); } catch ( SuccessException $e ) { $data = array('RESP' => 'OK', 'DATA' => $e->getData()); } catch ( Exception $e ) { $data = array('RESP' => 'ERROR', 'MSG' => $e->getMessage()); } if ( isset($_GET['js']) ) { echo json_encode($data); } else { return $data; } ?><?php // view_vehicle.php $data = include 'get_vehicle.php'; if ( strcmp($data['RESP'], 'OK') !== 0 ) { echo $data['MSG']; exit; } $data = $data['DATA']; echo 'Make: '. htmlentities($data['make'], ENT_QUOTES, 'UTF-8') . '<br >'; echo 'Model: '. htmlentities($data['model'], ENT_QUOTES, 'UTF-8') . '<br >'; echo 'Registration: '. htmlentities($data['registration'], ENT_QUOTES, 'UTF-8') . '<br >'; echo 'Price: £'. number_format($data['price'], 2) . '<br >'; echo '<p>'. htmlentities($data['description'], ENT_QUOTES, 'UTF-8') .'</p>'; ?><html> <head> <script type="text/javascript" src="jquery.min.js"></script> <script type="text/javascript"> <!-- $(document).ready(function() { $('body').append('<div style="display: hidden; position: absolute;" class="vehicle_div"><>'); $('.car_page_link').click(function(e) { e.preventDefault(); $.getJSON($(this).attr('href') + '&js=true', function(response) { if ( response.RESP.toLowerCase() != 'ok' ) { alert(response.MSG); return false; } $('.vehicle_div').html( 'MAKE: ' + response.DATA.make + '<br >'+ 'MODEL: ' + response.DATA.model + '<br >'+ 'REGISTRATION: ' + response.DATA.registration + '<br >'+ 'PRICE: £' + response.DATA.price + '<br >'+ '<p>' + response.DATA.description + '</p>' ).fadeIn('fast', function() { $('body').click(function() { $('.vehicle_div').fadeOut(); }); }); }); }); }); //--> </script> </head> <body> <a href="view_vehicle.php?vehicle_ID=1" class="car_page_link"><img src="McLarenF1.jpg" alt="McLaren F1" title="McLaren F1" ></a> <a href="view_vehicle.php?vehicle_ID=2" class="car_page_link"><img src="Ferrari F50.jpg" alt="Ferrari F50" title="Ferrari F50" ></a> <a href="view_vehicle.php?vehicle_ID=3" class="car_page_link"><img src="Bugatti Veyron" alt="Bugatti Veyron" title="Bugatti Veyron" ></a> </body> </html>Personally, I don't see the problem with light-boxes?
-
You should use progressive enhancement, this is just a 'jargon'd up' way of saying your site should function properly with javascript disabled, then you can switch things out with javascript after the content is loaded; in your example I would go for something like this:
<html> <head> <script type="text/javascript" src="jquery.min.js"></script> <script type="text/javascript"> $(document).ready(function() { $('.car_page_link').click(function(e) { //prevent href from loading e.preventDefault(); mylightboxlib.loadIFrame($(this).attr('href')); }); }); </script> </head> <body> <a href="car1.php" class="car_page_link"><img src="McLarenF1.jpg" alt="McLaren F1" title="McLaren F1" ></a> <a href="car2.php" class="car_page_link"><img src="Ferrari F50.jpg" alt="Ferrari F50" title="Ferrari F50" ></a> <a href="car3.php" class="car_page_link"><img src="Bugatti Veyron" alt="Bugatti Veyron" title="Bugatti Veyron" ></a> </body> </html> -
-
Better off with filter_var than regex:
$uris = array( 'www.google.com', 'http://www.google.com', 'google.com', 'rfdgedg' ); foreach($uris as $uri) var_dump(filter_var($uri, FILTER_VALIDATE_URL));
boolean false string 'http://www.google.com' (length=21) boolean false boolean false
-
Use a join, sorry I can't help more but it's 12:10am so I need to get my sleep for work. I'll help tomorrow (well, later today) if it's still not resolved
-
Doesn't seem to be, tested it with preview and it didn't work again, it's happened 3 times.
Below I'll enter [ nobbc ][ code ][ /code ][ /nobbc ] without spaces
<-- here
-
You will probably notice that I have to edit this topic before tags show.
//EDIT
You will probably notice that I have to edit this topic before [nobbc][/nobbc] tags show.
-
Wrap your code in
tags, and that's a lot of code to read, I doubt people will help unless you only post the code portion relevant to your problem.
-
mysql_fetch_assoc moves the specified results' internal pointer forward one step on each call, so just keep calling mysql_fetch_assoc.
<?php include 'db.php'; $query = "SELECT href, alt FROM images LIMIT 3"; $result = mysql_query($query); $row = mysql_fetch_assoc($result); ?> <img src="<?php echo htmlentities($row['href'], ENT_QUOTES, 'UTF-8'); ?>" alt="<?php echo htmlentities($row['alt'], ENT_QUOTES, 'UTF-8'); ?>" > <?php $row = mysql_fetch_assoc($result); ?> <img src="<?php echo htmlentities($row['href'], ENT_QUOTES, 'UTF-8'); ?>" alt="<?php echo htmlentities($row['alt'], ENT_QUOTES, 'UTF-8'); ?>" > <?php $row = mysql_fetch_assoc($result); ?> <img src="<?php echo htmlentities($row['href'], ENT_QUOTES, 'UTF-8'); ?>" alt="<?php echo htmlentities($row['alt'], ENT_QUOTES, 'UTF-8'); ?>" >
Alternatively, you could use mysql_result
<?php include 'db.php'; $query = "SELECT href, alt FROM images LIMIT 3"; $result = mysql_query($query); ?> <img src="<?php echo htmlentities(mysql_result($result, 0, 0), ENT_QUOTES, 'UTF-8'); ?>" alt="<?php echo htmlentities(mysql_result($result, 0, 1), ENT_QUOTES, 'UTF-8'); ?>" > <img src="<?php echo htmlentities(mysql_result($result, 1, 0), ENT_QUOTES, 'UTF-8'); ?>" alt="<?php echo htmlentities(mysql_result($result, 1, 1), ENT_QUOTES, 'UTF-8'); ?>" > <img src="<?php echo htmlentities(mysql_result($result, 2, 0), ENT_QUOTES, 'UTF-8'); ?>" alt="<?php echo htmlentities(mysql_result($result, 2, 1), ENT_QUOTES, 'UTF-8'); ?>" >
I am unsure of the speed implications of each method, I think mysql_fetch_assoc will be faster, but mysql_result looks cleaner IMO.
-
Hi Dan, I'm from Manchester(Stalybridge) too
 There's a PHP NW meetup at Rain bar in town of the first Tuesday of every month, it's free to go, and they have a different speaker each time, I haven't been yet but planning on going soon, seems like a good place to start?
There's a PHP NW meetup at Rain bar in town of the first Tuesday of every month, it's free to go, and they have a different speaker each time, I haven't been yet but planning on going soon, seems like a good place to start?Everyone's pretty helpful here, stick around and I'm sure you'll pick it up

I've been programming for 7 years and still copy and paste the DTD, it's no big deal.
-
Both can handle multi-dimensional arrays, but I don't see much reason to manually loop through the array, when you can use a native function to do it for you.
Although her code allows you to set the ENC type flag and character encoding.
@Debbie
array_map will be faster than foreach as it's a native PHP function so the looping is executed in C and doesn't need to be interpreted. Although the difference in execution time will not be significant in this case.
If you are running PHP >= 5.3 and are pretty sure you always will, my array_map_recursive code will allow you to specify parameters and use a native function, but to be honest, if you understand how your function works, just go with that.
As for knowing whether the function has worked:
function str2htmlentities($input, $type=ENT_QUOTES, $char='UTF-8'){ if (is_array($input)){ foreach ($input as $key => $value){ $input[$key] = str2htmlentities($value, $type, $char); } return $input; }else{ return htmlentities($input, $type, $char); } } $array = array('<>', array('"<>"'), '">'); $array = str2htmlentities($array); echo '<pre>'. print_r($array, 1);View page source should output < as > > as < and " as "
-
I tweaked the function like this...
function str2htmlentities($input, $type=ENT_QUOTES, $char='UTF-8'){ if (is_array($input)){ foreach ($input as $key => $value){ $v = str2htmlentities($value, $type, $char); } return $input; }else{ return htmlentities($input, $type, $char); } }Is that way okay??
It seems to work, but I am still a little shaky on what is going on even as I step through the code in NetBeans. (NetBeans takes a few strange hops as you cycle through everything?!)
Debbie
$v doesn't exist there, should be:
function str2htmlentities($input, $type=ENT_QUOTES, $char='UTF-8'){ if (is_array($input)){ foreach ($input as $key => $value){ $input[$key] = str2htmlentities($value, $type, $char); } return $input; }else{ return htmlentities($input, $type, $char); } } -
Come to think of it, wrapping it in a function and encapsulating how you escape output can't be a bad thing anyway, even if you are escaping as-and-when necessary.
-
I would still use array_map(), but in such a way that it will work for multidimensional arrays. For the encoding you can just define it inside the function.
function entities($input) { if (is_array($input)) { return array_map('entities', $input); } return htmlentities($input, ENT_QUOTES, 'UTF-8'); }EDIT: Fixed a typo in code
1.) Shouldn't it be...
return array_map('htmlentities', $input);2.) How is your code different from mine?
3.) How does your code handle a multi-dimensional array?
I don't see how it is recursive like scootstah's code.
Debbie
1. Nope, that's how it's recursive, it "calls itself", although this can be achieved another way
function entities($input, $quotes = ENT_QUOTES, $charset = 'UTF-8') { if ( is_array($input) ) { array_walk_recursive($input, function(&$v, $k, $params) { $v = htmlentities($v, $params[0], $params[1]); }, array($quotes, $charset)); return $input; } return htmlentities($input, $quotes, $charset); }2. I can't work out whose code is whose anymore lol, probably that it uses a built-in PHP function rather than foreach.
3. It's recursive, so:
$arr = array('on>', array('tw>'), '"thr'); // first iteration function entities($input) { // [ 'on>', [ 'tw>' ], '"thr' ] is array, map it with entities function (run entities on each value) if (is_array($input)) { return array_map('entities', $input); } return htmlentities($input, ENT_QUOTES, 'UTF-8'); } // $arr = array(); // second iteration function entities($input) { { return array_map('entities', $input); } // 'on>' is not array, return htmlentities return htmlentities($input, ENT_QUOTES, 'UTF-8'); } // $arr = array('on>'); // third iteration function entities($input) { // [ 'tw>' ] is array, map it with entities function (run entities on each value) if (is_array($input)) { return array_map('entities', $input); } return htmlentities($input, ENT_QUOTES, 'UTF-8'); } // $arr = array('on>', array()); // fourth iteration function entities($input) { if (is_array($input)) { return array_map('entities', $input); } // 'tw>' is not array, return htmlentities return htmlentities($input, ENT_QUOTES, 'UTF-8'); } // $arr = array('on>', array('tw>')); // fifth iteration function entities($input) { if (is_array($input)) { return array_map('entities', $input); } // '"thr' is not array, return htmlentities return htmlentities($input, ENT_QUOTES, 'UTF-8'); } // $arr = array('on>', array('tw>'), '"thr');Hope that helps, for the record I wouldn't do it this way at all, I'd use the way you were already doing, that way you only need to store one variable, and can escape it as-per for MySQL, display etc.
If you wish to make it more bearable the "ENT_QUOTES" constant resolves to (int)3 so you could use:
htmlentities($in, 3, 'UTF-8');
As far as character encoding, I always use UTF-8, it's the go-to-encoding if you don't know anything about character encoding (like myself), and just make sure everything's in sync, I.E.
HTML pages have:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" >
PHP (untrusted variables) are output using:
htmlentities($var, 3, 'UTF-8');
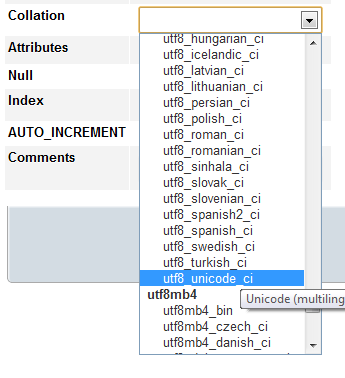
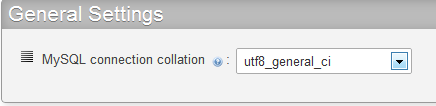
MySQL charset (default is 'latin1_sweedish_ci') is set to utf8_general_ci or utf8_unicode_ci (see attachment), and you run:
mysql_query("SET NAMES 'UTF8'"); // or PDO $dbh = new \PDO('mysql:dbname='. DB .';host='. DB_HOST, DB_USER, DB_PASS); $dbh->setAttribute(\PDO::MYSQL_ATTR_INIT_COMMAND, "SET NAMES 'UTF8'");And you should be OK.
-
Well you're obviously a pr0-1337 programmer, like this guy -->
Write your own OO interpreted server-side programming language?
-
Or how about an analogy that hits closer to home. You are obviously a coder. So the chances are very high you have your own circle of people who automatically think that just because you touch a computer, you are an expert on everything having to with computers. That's why your grandpa calls you up asking you to fix his shit when he's clicked on too many links from nigerian princes promising riches and 10 hour erections. And what do you say to that? "Sorry grandpa, I do web development, I don't know how to clean old-man splooge from a usb port". Does that make you a bad programmer? No! It just makes you bad at cleaning up your grandpa's taint (And I'm not judging, I too have trouble cleaning up my grandpa's taint, no worries bro).
PMSL, legend!
-
I think everyone should ignore it, on the premise that politicians, who've probably never even seen a line of code in their life, never mind written one, and think that a cookie is:
"A small sweet cake, typically round, flat, and crisp."
shouldn't be passing law's about such things.
-
PHP6 may as well still support procedural programming since Amateurs need it
There's nothing amateurish about procedural programming. Period. Full stop. You continuing to assert it does not make it true. Indeed, all you're showing is your own inexperience.
The fact is that in early days some theory/methodology did not exist in the world of programming. It is the ultimate intelligence of human beings to create something out of nothing, you can say the one who first proposed OOP was one of the smartest guys in the world. However, you cant say those who did not use OOP back in the days when it was not there or not yet realized as a superior programming paradigm were stupid. Hopefully this time I am being clear enough.Again, you don't know what you're talking about. OO has been around, in terms of languages, since the 1970's. Its theoretical underpinnings since the 1950's. OO isn't some new discovery which is self-evidently better than everything else.
There are very real reasons why OO isn't used in every situation. Off the top of my head:
Code bloat
Memory overhead
Memory management
No great way to handle true decimal math (reliance on floating point)
---
Since you keep asserting that OOP is what true professionals use (even though that's wrong), what is it that OOP does that's different/better than everything else in your eyes?
Encapsulates amateur code? lol

DOMDocument or preg_match_all
in PHP Coding Help
Posted
$doc = new DOMDocument('4.01', 'UTF-8'); $doc->loadHTML('<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> <html lang="en"> <head> <title>Phantom - Tracking Ststems and Accessories</title> <!-- META //--> <meta name="description" content="" > <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" > <!-- LINKS AND SCRIPTS //--> <link rel="stylesheet" href="css/layout.css" type="text/css" > </head> <body> <div id="clouds"><> <div id="container"> <!-- HEADER //--> <div id="header"> <h1> <a href="/"> <img src="images/layout/b2c/phantom.png" alt="Phantom vehicle tracking and accessories" > </a> </h1> <div id="header_right"> <ul id="header_nav" class="navigation"> <li class="first"><a href="#">About</a></li> <li><a href="#">News</a></li> </ul> <img class="telephone" src="images/layout/b2c/tel.png" alt="Telephone number" > <> <> <!-- SLIDER //--> <div id="slider"> <> <!-- PRODUCT NAVLIGATION IMAGES //--> <ul id="product_navigation"> <li class="first"><a href="#" id="remap">Engine ECU remapping</a></li> <li><a href="#" id="tyre-pro">Tyre protector</a></li> <li><a href="#" id="sat-dish">Caravan and motorhome satellite dish</a></li> <li><a href="#" id="reverse-sensor">Reverse sensor</a></li> <li><a href="#" id="in-car-cam">In car camera</a></li> <li><a href="#" id="alarms">Caravan and motorhome alarms</a></li> <li><a href="#" id="tracking">Caravan and motorhome tracking</a></li> <li><a href="#" id="subs">Renew tracking subscription</a></li> </ul> <!-- CONTENT //--> <div id="content"> <div class="clr"><> <> <> <!-- FOOTER //--> <div id="footer"> <div id="logo"><> <div class="green_banner"> <div id="motto">Protect, Secure, Enjoy<> <> <div class="blue_banner"><> <> </body> </html>'); $frag = $doc->createDocumentFragment(); $frag->appendXML(' <!-- MAIN NAVIGATION //--> <ul id="main_nav" class="navigation"> <li class="first"><a href="#">Home</a></li> <li><a href="#">Tracking</a></li> <li><a href="#">Remapping</a></li> <li><a href="#">Tyre protector</a></li> <li><a href="#">Alarms</a></li> <li><a href="#">Cameras and sensors</a></li> <li><a href="#">Insurance</a></li> <li><a href="#">Contact us</a></li> </ul>'); $doc->getElementById('container')->insertBefore($frag, $doc->getElementById('slider')); echo $doc->saveHTML();Seems to work quite well, as long as I add the /> for non-closing tags, but it outputs them correctly
Cheers