kicken
-
Posts
4,704 -
Joined
-
Last visited
-
Days Won
179
Everything posted by kicken
-
You should be connecting only once. Creating the database connection involves a lot of overhead in setting up the TCP/IP Connection, initializing settings, etc. This is something you want to do only once then run all your queries using the same connection. You want to only create your connection once and just reference it each time you need to run a query. Have a function to do the connection for you and save the connection to a variable. Have your query functions accept a parameter which is the connection to use for running the query. A nice way to do this is to wrap it all up in a class so you can store the connection variable as a class level variable. MySQLI already supports an OOP style setup which you should be able to just extend to add whatever functionality you may want. Eg: class DB extends MySQLi { public function udb_query($query){ if (!$this->select_db(USER_DATABASE)){ die('Could not change database'); } $res = $this->query($query); if (!$res){ die('Error running query'); } return $res; } public function promo_query($query){ if (!$this->select_db(PROMO_DATABASE)){ die('Could not change database'); } $res = $this->query($query); if (!$res){ die('Error running query'); } return $res; } }
-
read up on flush and ob_flush.
-
Once you've aliased a table in a query, then you need to refer to it by it's alias name (and only that). Notice I just used c.ClientId not Clients c.ClientId Aliasing is useful to shorten the table names and reduce the amount of typing you have to do in the query if you need/choose to prefix your fields with a table reference. Aliasing is also necessary if you need to join the same table twice. For example if you had a message table and a message had two user ID's, one for FromID (Who sent it) and ToID (Who receives it) and you want to display their names, you'd do something like: SELECT f.Name as fromName , t.Name as toName FROM messages m INNER JOIN users f ON m.FromID=f.UserID INNER JOIN users t ON m.ToID=t.UserID
-
Uncaught ReferenceError: iimPlay is not defined auto.php:62 You're not defining that function anywhere. You need to either include the appropriate library or create the function.
-
More or less, except for the case of the LEFT JOIN (Table C) nothing is discarded if there are no matches. Instead of discarding the row it is "joined" to a single row consisting of all NULL values. Basically any field from Table C would just have the value NULL when selected. As I said, you can think of it as creating a bunch of little boxes to hold the different rows. Each box is labeled by the columns listed in the GROUP BY clause. See the diagram, might help make sense of it. Based on my fiddle above. In applies to both. You may see it a lot in example queries on the forums and such simply because it's easier to type and we often do not know what a user's column names actually are. When writing your actual queries though you should not use it. I use it in only two cases: 1) On the forums sometimes when posting sample queries 2) When building/debugging queries during development in a tool like Mysql Workbench/PhpMyAdmin. Once the query is working propery and ready to be put into your script, list out the columns you need. Take for example a setup like these forums. On the forum listing page all you really need is the title, ID#, and author name of each topic. You don't need the post data or any extra author info. If you were use * you'd get all that extra junk though which is just going to eat up unecessary memory in PHP and bandwidth between PHP and the sql server. As an added benefit if by chance all the columns you need are indexed mysql can pull the values straight from the index and not have to hit the table's datastore at all which lets the query run entirely in RAM and not have to wait for any disk I/O which is the main cause of slowness. In the from and join clauses I set the alias for the table. ... FROM Clients c INNER JOIN Jobs j ... The c and j are the table aliases. That bit essentially means "...From the Clients table (which will now be known as 'c') Join with the Jobs table (which will now be known as 'j') ..."
-
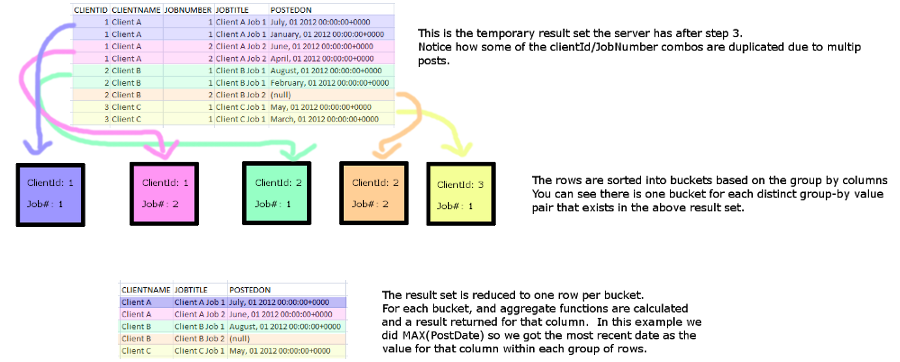
One thing: You shouldn't use * in your column list. Especially with GROUP BY also in the query, however never using it is ideal. If certain options were set on your sql server, your query would start failing with an error about trying to select non-aggregate columns. List out only the columns you actually need to use in your page so that you select only those columns. It will reduce the work the server has to do, better document your code, help prevent problems from table structure changes, and more. Basically what is going on there is something like this, in a rough step-by-step process. 1) The server first selects all the rows from the clients table. 2) For each of the above rows, it checks the Jobs table for any rows where the given join condition (ON c.ClientId=j.ClientId) is true. It then combines the found rows with the row from the Clients table (duplicating the Clients table row if necessary). If no rows in the Jobs table are found matching that condition, then the row from the clients table is elimiated from the final results. 3) For each of the above rows, it then checks the Posts table for any rows that match the given join condition. Any rows that match are merged into the result set (again duplicating the fields from Clients and Jobs as necessary to fill out all the rows). If no rows are found, and fields from the Posts table are treated as being NULL. -) What you have at this point as a result is all the rows matching the given conditions. Next the server applies the group by 4) Groups the rows by the given group by directive. Any rows that have the same values in the columns referenced by the group by directive get lumped together. Like sorting all the rows into a bunch of little boxes where each box is a unique combination of the GROUP BY columns. 5) Next the server applies any aggregate functions in the query. In this case the MAX function is applied to the PostDate column. The server will look at each group and determine what the MAX (most recent) PostDate is and use that value in the result set. -) At this point you'll have your final result set. For any columns not listed in the group by and not used in an aggregate function, mysql will pick a value at random from one of rows of the group to fill in that value. 6) Lastly the server applies any sorting operations to the result set just before returning it to your PHP code. In this instance, it sorts it by the MAX(PostDate) (referenced via it's alias of postDate) column in descending order. Most-recent to oldest essentially.
-
Every request is completely independent of any previous (or future) requests. The variables you set during one request are not set during any other request (general exception is $_SESSION variables). Generally speaking the scripts simply run in a top-down fashion, from line 1 to line X, whatever that may be. Each time the script starts it's execution at line 1, the environment is completely clean as if that script (or any other) had never been run before. If you want to use something, you have to ensure that it is made available prior to your attempt to use it. This means you either have to pass the data from script to script (ie, using $_SESSION, $_POST, $_GET, etc) or you have to re-acquire that data from the database/file/whatever.
-
http://sqlfiddle.com/#!2/76be3/1/0
-
There is no way you're going to format PHP's print_r output into something presentable to an end-user using css. print_r is for debugging use only. You need to be able to use PHP to get the information and format it that way.
-
Either limit the query using a WHERE clause to a single client, or add the client id into the GROUP BY so it groups on the combination of the client id and job number. You'll probably need to modify the left join's ON condition to include a client id match also if the job numbers are re-used for different clients, otherwise client #12345 would see there job number 1 light up as having a new unread post when something gets posted to client #12346's job number 1.
-
Yes. You need to prefix it with the table name you want to pull the field from. That would be the Jobs table in this case, so: SELECT Jobs.JobNumber, MAX(PostDate) as postDate FROM Jobs LEFT JOIN Posts ON Posts.JobNumber=Jobs.JobNumber GROUP BY Jobs.JobNumber ORDER BY postDate
-
Use mysql_error to figure out why your query is failing.
-
include $_SERVER['DOCUMENT_ROOT'].'/template.php'; When dealing with file paths in PHP, '/' refers to the file-system root, not the root of your domain. You can determine the root of your domain using the $_SERVER['DOCUMENT_ROOT'] variable.
-
For the sorting, join to the posts table and then ORDER BY the post's date. Use GROUP BY to just get the max date. Something like this: SELECT JobId, JobTitle, MAX(PostedOn) as postedOn FROM jobs LEFT JOIN posts ON posts.JobId=jobs.JobId GROUP BY JobId, JobTitle ORDER BY postedOn As for the unread indicator, you'll have to add a column to the posts table indicating whether that post is read or not. Whenever a client views the post then update that column to indicate it has been read. When you select your list of jobs, check for and unread rows using that column.
-
If I am understanding your requirements correctly, and have deduced your table structure correctly, then your entire script can be replaced by this query: UPDATE leads l LEFT JOIN ValidISP v ON l.IPISP=v.ISP SET l.IPCheck=COALESCE(v.Status, 'MANUAL') WHERE l.IPCheck='NO' What that will do is go through each row in leads where IPCheck='NO' and match it up with a row from ValidISP using the condition leads.IPISP=ValidISP.ISP (ie, the IPISP column's value is equal to the ISP columns value). Then it will assign the value of leads.IPCheck to whatever ValidISP.Status is currently set to, or 'MANUAL' if no matching row can be found.
-
The query string data is supposed to be separated from the file by a question-mark. Your using an ampersand right now. .../dillon_original.jpg?h=54&w=80&zc=2
-
Re-structure your page so the PHP code to process the form comes before your HTML, then if the form was submitted successfully output your refresh header and your thank you message. Use variables to hold your messages and then output them later in the proper place in your HTML.
-
I do use the editor with the rich-text stuff disabled. Does not seem to matter one way or the other though, the same thing happens. I'm not sure what is going on with it to cause the problem. Windows-style line breaks may be a possibility. It is odd that it only happens with blank lines though and not every line break. It looks like it's probably fixed in the next version though. We'll see.
-

Inserting from a 61,000 record text file - does 1 1/2 hours sound right?
kicken replied to phpjim's topic in PHP Coding Help
You should temporarily disable the indexes on the table prior to do trying to insert all the records. You can do this using ALTER TABLE Also if you are not already doing so, you should be using the bulk insert syntax rather than doing one insert per row. INSERT INTO table VALUES (...), (...), (...) Lastly you might check your configuration for mysql. It may be configured to not use very much memory (I think this is typical for a development install) which means it might be doing a lot of disk I/O. -
Could be nice, so long as it works good. JSFiddle's attempt to highlight/auto-indent stuff generally causes more trouble than anything else for me. Dunno if it's just a chrome issue or what but it seems pretty buggy.
-
Looking for Good Example of Form Validation
kicken replied to HenryCan's topic in Application Design
The way I handle forms basically boils down to something like this: $Defaults = array(); $Errors = array(); if (count($_POST) > 0){ $Defaults = $_POST; //validation stuff if (count($Errors) == 0){ //process } } if (empty($Defaults)){ //Load defaults from DB if necessary } //Show form Within the template file for the form I use the $Defaults and $Errors variables to pre-fill form fields and display any error messages. A more complete example would be like this (a simple contact form). contact.php <?php $Defaults = array(); $Errors = array(); if (count($_POST) > 0){ $Defaults = $_POST; if (empty($_POST['contactName']) || strlen(trim($_POST['contactName']))==0){ $Errors[] = 'Name is a required field.'; } if (empty($_POST['contactEmail']) || !filter_var($_POST['contactEmail'])){ $Errors[] = 'Email is a required field.'; } if (empty($_POST['message']) || strlen(trim($_POST['message'])) == 0){ $Errors[] = 'Message is a required field.'; } if (count($Errors)==0){ $message = " You have receive a contact request from {$_POST['contactName']} ({$_POST['contactEmail']}). The message left was: ---------------------------------------------- {$_POST['message']} ---------------------------------------------- "; if (!mail("myemail@example.com", "Contact Request", $msg)){ $Errors[] = 'Unable to send your message. Please try again later.'; } else { include('thankyou.tpl'); exit; } } } include('contact.tpl'); ?> contact.tpl <!DOCTYPE html> <html> <head> <title>Contact me</title> </head> <body> <form method="post" action="contact.php"> <?php if (!empty($Errors)): ?> <ul> <?php foreach ($Errors as $err): ?> <li><?=$err?></li> <?php endforeach; ?> </ul> <?php endif; ?> <p>Name: <input type="text" name="contactName" value="<?=htmlentities($Defaults['contactName']);?>"></p> <p>Email: <input type="text" name="contactEmail" value="<?=htmlentities($Defaults['contactEmail']);?>"></p> <p>Message:<br><textarea name="message" rows="10" cols="60"><?=htmlentities($Defaults['message'])?>"><textarea></p> <p><input type="submit" value="Send Message"></p> </form> </body> </html> I just whipped that up in a few minutes here. As is it will show some E_NOTICE errors for undefined indexes, didn't test at all so may not even function right. It should demonstrate fairly well though. I have a template system I use in my production stuff that normally would handle preventing the E_NOTICE errors. One could wrap up some of the validation stuff into a library to make it a little less tedious also. -
One issue I've notice with the editor is that it always seems to quadruple my spacing whenever I paste something into the editor. Only happens around blank lines. Any idea if this is fixed in an upcoming IPB update? For example, this is what I type into Edit+ (Fixed spacing to match) class MyClass { public $a; private $b; public function __construct(){ } } When I paste it into the editor though it comes out like this: class MyClass { public $a; private $b; public function __construct(){ } }
-
copy paste code from phpfreaks
kicken replied to stijn0713's topic in PHPFreaks.com Website Feedback
If the original post's code is properly indented, then it should copy into your editor indented as well (works fine for me anyway). If the original post is not indented however, you'll need to use one of the re-formatting methods mentioned to fix it up (or just do it yourself). Unfortunately the editor used for posting is buggy and often removes all indentation from code when people paste it. -
I used to work on some IIS setups that did not define DOCUMENT_ROOT for some reason, though if I remember correctly, there was a similar variable, just went by a different name. Since then I've gotten into the habit of always define'ing my own DOCUMENT_ROOT constant based on __FILE__. I can't remember which IIS version it was that did that. The newer version we are using now does define it properly.
-
Use a <pre> tag to preserve whitespace. Or apply the white-space: pre; setting via CSS to your div.