.josh
-
Posts
14,780 -
Joined
-
Last visited
-
Days Won
43
Everything posted by .josh
-
My 61 y/o mom does database entry and data mining, she can make db queries that even fenway would be proud of...but when it comes to absolutely anything else with computers...seriously, I've had the "did you check if it's plugged in? ... yep, that would do it..." moments with her. Older generation people .. they weren't really around computers all their lives, esp as younger kids who could just mash buttons and see what happens. They were put in front of computers and taught to push very specific buttons, do very specific things, and nothing else.
-
Yeah, I've used the "retard talking to mechanic" analogy a lot of times in tl;dr posts...pretty good go-to analogy.
-
There is a "workaround" that effectively does the same thing. On the top right or bottom right of a thread is a "Notify" button. You can click on it to set the thread to notify you if people post in it. Now, if you go to Profile > Notifications You will see a listing of all threads you want to be notified on. Also on this screen you can change it to where you do not actually get notifications if you don't want to actually get notified.
-
Numbers calculated using this benchmarking function. Round 1: times executed (each): 250000 fastest to slowest: Array ( [josh_pure] => 0.00000539963519708157 [ManiacDan] => 0.0000057829462635701 [josh_blended] => 0.0000060079560636085 ) biggest difference time: 0.00000060832086652693 fastest is 11.266% faster than the slowest Round 2: times executed (each): 250000 fastest to slowest: Array ( [josh_pure] => 0.00000552566420531364 [ManiacDan] => 0.00000584143936571746 [josh_blended] => 0.00000610485283878271 ) biggest difference time: 0.00000057918863346907 fastest is 10.4818% faster than the slowest Round 3: times executed (each): 250000 fastest to slowest: Array ( [josh_pure] => 0.00000537841102728821 [ManiacDan] => 0.00000559228 [josh_blended] => 0.00000604077199996 ) biggest difference time: 0.00000066236097267179 fastest is 12.3152% faster than the slowest 18165_.txt
-
pure regex: if ( preg_match('~^[a-z]*-?[a-z]*$~',$string) ) { // valid } else { // invalid } blended...may possibly be a little faster: if ( (substr_count($string,"-")<=1) && (preg_match('~^[a-z-]$~',$string)) ) { // valid } else { // invalid }
-
kinda hard to help you without seeing any code... but if I had to guess, your icon swapping function sounds like it is working but your form is submitting anyways. IOW you're forgetting to return false somewhere, to block it from actually submitting. And I can only guess (again, no code posted) that you have a single form script that submits to itself and it's just outputting the original form again because of some server-side logic telling it to do it if form has not been filled out.
-
need the "s" modifier so that your "." will match newline chars.
-
This will throw those 3 chars into the mix, to match up to. It says to match one or more of anything that is not a space, comma, pound or colon: $description = preg_replace("/#([^ ,#:]+)/", "<a href=\"https://twitter.com/#!/search/%23$1\">#$1</a>", $description); or alternatively, this will just match one or more word char (letter, number or underscore) $description = preg_replace("/#(\w+)/", "<a href=\"https://twitter.com/#!/search/%23$1\">#$1</a>", $description);
-
create a duplicate profile with same filters and wait a week or two for some traffic to flow in. Remove the filter on the dupe and wait another week or sooner to compare numbers with main profile.
-
We also have in red letters above the post buttons a warning....
-
Okay so the way your pattern works... 1) You are using ^ as the pattern delimiter. While it is technically okay to use (most) non-alphanumeric characters as the pattern delimiter, you should avoid using characters that have special meaning to the regex engine. ^ is a marker to signify start of string or line (depending on modifiers used), and also used for negative character classes, so you want to avoid that. I use ~ in as my delimiter because it has no special meaning to regex engine and it also rarely comes up in the subject I need to regex. But on the note of specifying start (and end) of string... 2) Your pattern does not specify start or end of string. What this means is that your pattern will not just match for example "D34V78", it will also match "anythinghereD34V78orhere". So in order to tell the engine to evaluate the string as a whole, IOW "the entire value of this string must be this format, not just some substring within it", you have to specify beginning and end of string, with ^ and $, respectively. 3) Wrapping your (sub)patterns in parens (...) (capture groups) is what makes the captured bits of your pattern show up as individual array elements. So your pattern does not wrap that first D in parens, so it will not show up as a captured element. I did mention in my post how I thought this was indeed not necessary, since you said that the string will always start with D, but technically you did specify that it be listed within the matched array, which is why I edited my pattern to capture it. 4) This bit of your pattern: ([A|E|V]) This *works* but it will also match a pipe, for example "D123|456" will match. Why? Okay square brackets [..] is a character class. It will match for one character listed inside the brackets (or match for a character NOT listed in it if ^ is the first character listed within the brackets). So basically that pattern is saying "match for an 'A' or a '|' or an 'E' or a '|' or a 'V'" so basically you just list a pipe 3 times. I can see why you thought to separate the characters with a pipe though, since that is the alternation character. You would normally use the pipe if you want to match for "abc" or "xyz" where the match is more than a single static character (or character range), since a character class will only match for ONE character in the list. IOW, abc|def will match "abc" or "def" but [abcdef] will match "a" or "b" or "c" or "d" or "e" or "f". And [abc|def] just matches the same thing or a pipe. Sidenote: even though character classes can only match for any ONE character in the list, and they must be literal characters (with the exception of escaped characters to signify certain other characters), you CAN specify ranges, such as 0-9 will match for a 0 or 1 or 2 or ... 9 (you get the picture). Which you will see demonstrated in the pattern. So, having said all that, here is the breakdown of my pattern: ~^(D)([0-9]+)([VAE])([0-9]+)$~ ~ pattern delimiter ^ start of string assertion (cannot have anything before what follows) (D) match for and capture a literal "D". As mentioned, IMO capturing it is not necessary since you say it will always be "D". ([0-9]+) match for and capture 1 or more of any single digit number ([VAE]) matched for and capture a "V" or "A" or "E" ([0-9]+) match for and capture 1 or more of any single digit number $ end of string assertion (cannot have anything after the pattern) ~ pattern delimiter So it basically reads as "start at the beginning of the string and match and capture a 'D', followed by 1 or more numbers, followed by one of these 3 characters, and ending with 1 or more numbers"
-
$string = "D34V78"; preg_match('~^(D)([0-9]+)([VAE])([0-9]+)$~',$string,$parts); print_r($parts); Array ( [0] => D34V78 [1] => D [2] => 34 [3] => V [4] => 78 ) edit: I added a capture group around the first "D" because I noticed you said you wanted the array to include it...but if you say it will ALWAYS Start with D, then I'm not sure why you really *need* it to be captured, but there you have it.
-
ouch...that's a real eye-opening experience, about the dependency we have on sight! I bet it was very enl-eye-ghtening! aHAHAHAhaHAHAHa! No but seriously, that must have sucked
-

Anybody know of something of the best Jquery debugger it is?
.josh replied to Redlightpacket's topic in Javascript Help
-
To directly answer your question, yes, it is possible to "get by" using Linux w/out a command prompt. There are a lot of distros out there that focus on providing an alternative to Windows but with all the "GUI" benefits that make Windows so popular.
-
you should..probably ask on a more appropriate site, or better yet, ask an optometrist. This is a web development site...this question is so off-the-wall, frankly I'm inclined to suspect spam...
-
How Does PHPFreaks Feel About the Hate PHP Often Gets as a Language?
.josh replied to Masna's topic in Miscellaneous
I probably don't really need to state the obvious, but considering this is a php site and we are named phpfreaks, I suspect opinions about php will be biased towards php... -
The patent process, and really any U.S. legal process/system/etc.. is actually pretty simple: whoever has the most money to throw at it wins. You can even get away with murder (literally!) if you have enough money to throw at it. Someone takes your code? Take them to court. Because it will cost him money to defend himself. If he wins, sure, you'll have to pay. But...you can appeal, in which case he has to pay to defend himself all over again and get it back from you if he wins all over again. If you lose, appeal. If you lose again, appeal again. Wash, rinse and repeat until whoever has the most money wins. The only reason you see people "losing" or "settling" is because a) they ran out of funds to keep it going, or b) they decide they will lose too much money in the long run (eg: Big Chemical Co. may be blatantly torturing and killing animals while "testing" Brand X but they will certainly get away with it legally if they throw enough money at it...but if enough people decide they won't buy their products, then they are fistcally fucked, so they back down or compromise - which is not really the same thing). Yes it really is that simple, sad and true. In a capitalist system, money is god.
-
// strip everything but the numbers $number = preg_replace("~[^0-9]~","",$number); This already strips whitespaces and will effectively trim() it; it strips anything that is not a number. And then this: // number is bad if not 10 digits if ( strlen($number)!=10 ) return false; checks to see if what is left over is 10 chars. So basically, the visitor can enter in a phone number in any format they wish, (even " [123]....(456)~7890~ " if they really really wanted to - I hear that's the unofficial format of some smaller towns in Nebraska backwoods areas).
-
Speeding up server connection waiting time
.josh replied to jnich05's topic in PHPFreaks.com Website Feedback
This is what I got from the test. Faster than 91% of all tested websites! Anyways...near as I can tell, most of the load/wait time comes from the 3rd party ads (something you don't get if you become a supporter or named membergroup).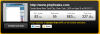
-
This is pretty much what I do, as well. At face value I can see why people would do that, especially in a loosely typed language like php. But yeah...nonetheless, I too find it annoying.
-
Hello Shadowing, It looks like you want to 1) Match for a standard American telephone number 2) Reject certain phone numbers because they are fake. #1 is fairly easy, especially if you take the approach of not caring what the actual format is (different people use different formats; some people wrap the area code in parens, some people use hyphens while others use dots, etc...) by just stripping out anything that is not a number and then counting for 10 digits. #2 on the other hand is pretty arbitrary. The only realistic thing you can do is either a) have a whitelist of all valid U.S. phone numbers. This is not feasible because it is a very large, ever changing list. Or b) make a blacklist of the more common bullshit numbers people try to use. This is by far more feasible, but it will never be perfect, and there's no way to really make anything perfect, short of attempting option "a". One possible compromise would be to make a whitelist of all currently known area codes. The list isn't all *that* long, but more importantly, even though the area code list can change...it is not something that changes very often. You can even see from the link a bunch that aren't actually in use yet but are reserved or up and coming. Yeah..still kinda a pita to maintain but you shouldn't have to check very often. So anyways, I separated area code and local number black lists into two separate arrays in code below so it will be easier to go that route if you wanna. But also since it is separated, will have the added bonus of catching numbers like '1110000000'. But as far as the local number blacklist...TBH I would not recommend adding anything else to that list. For example, one of your "baddie" phone numbers "6661234" ...this is more than likely a valid number. I know for a fact that "666" is a valid local prefix in some areas, and I'm almost 100% positive most phone companies just randomly pick the last 4 digits or pick the "next available increment" when assigning you a phone number. So anyways, with all that in mind, here is my suggested solution (this is example code to get the concept...you may wanna organize this how you see fit, according to whatever other code you have...for example, make the blacklist some object property etc...): function validatePhoneNumber ($number) { // black list of common fake area codes $blacklist['a'] = array('000','111','222','333','444', '555','666','777','888','999', '123','098','987'); // black list of common fake local numbers $blacklist['l'] = array('0000000','1111111','2222222','3333333','4444444', '5555555','6666666','7777777','8888888','9999999', '4567890','7654321','1234567','6543210'); // strip everything but the numbers $number = preg_replace("~[^0-9]~","",$number); // number is bad if not 10 digits if ( strlen($number)!=10 ) return false; $a = substr($number,0,3); $l = substr($number,-7); // number is bad if area code in blacklist if ( in_array($a,$blacklist['a']) ) return false; // number is bad if local number in blacklist if ( in_array($l,$blacklist['l']) ) return false; // number is good return true; }
-
We cannot really enforce sticky orders, it's not how SMF works. Stickies are ordered same way as non-stickied: most recent response response (last post descending), and you can reorder by clicking on column headers. There is no way to say "no matter what, make this sticky #1". But you make a fair enough point about adding to it, so I unlocked it. Regex for the most part hasn't really changed though, so even if the resources are *old*, if the links still work (not gonna lie, haven't checked), they should still be viable. But again, you make a fair point about being able to contribute new links/tuts, so I unlocked the thread and merged your thread with it. My guess is it was probably a more popular topic back then and so someone decided to sticky it. Or...someone could have been particularly proud of the solution and happened to have powers to sticky...who knows. In any case, I will agree that it doesn't currently warrant being stickied. Thread unlocked. Gonna have to disagree on this one. I think I'm going to have to dust off my copy and recheck, but I coulda swore it did in fact cover \K...and pretty much everything under the sun. Sure, there have been *some* changes to regex since 2006, but truth is, despite its age, this book remains king of "learn absolutely everything you ever wanted to know about regex". I challenge you to find a more thorough, more recent, etc.. book. Even for the changes that have been made since then...they aren't for beginners or even intermediates anyways. But I will agree it doesn't deserve a separate sticky from a "resources" thread, so I unstickied it.
-
This topic has been moved to FAQ/Code Snippet Repository. http://www.phpfreaks.com/forums/index.php?topic=122857.0
-
sidenote @ ragax: you use commas for pattern delimiters? eww ... that makes for unnecessary escaping should you need to for instance do [0-9]{1,10}