gizmola
-
Posts
6,086 -
Joined
-
Last visited
-
Days Won
156
Everything posted by gizmola
-
Just as I posted, I saw your reply, however, the points I have made and sample code are still things you should consider.
-
The answer is that you are always getting the last row in the result set. Consider your current code. You query, then in a loop fetch every row from the result set and assign the values from the row to various temporary variables of the same name and purpose. First off, not to fix your problem, but --- there is no reason to do this. You get an associative array with the values nicely indexed by column name. Don't make a bunch of temporary variables when you don't need to. Just use $row['field'] when you need to display the value. Yes, you absolutely need to change your query to take the id passed to the script. According to what you provided that should be $_GET['id']. I don't know why that hasn't worked for you yet, but that's the correct way to do this, although, you should be using a prepared statement and bind variable rather than trying to interpolate the variable. Do it the right way. Consider the interpolation example you provided: SELECT * FROM users WHERE id = '$id' " This is incorrect if id is an integer, which we have to assume it is, since this is a numeric id. So you should not put quotes around it, because it is not a string. With that said, the mysqli_ binding probably allow this but it's sloppy and incorrect SQL. In summary, there may be an issue with the id, so make sure you debug that you are getting the value you expect from the $_GET array. (This also assumes you reach this page via an anchor href). We don't have the code to know for sure what you are doing. if (empty($_GET['id']) { // this page shouldn't be entered, because no valid id was passed // maybe redirect? exit("invalid"); } $id = (int)$_GET['id']; $sql = "SELECT * FROM users WHERE id=?"; $stmt = $conn->prepare($sql); $stmt->bind_param("i", $id); $stmt->execute(); $result = $stmt->get_result(); $user = $result->fetch_assoc();
-
So what people are trying to say is that something must run the submit_rating.php when a review is posted. The same script needs to be run when a page is loaded, as it returns the data you need for your page to update the numbers you want to see updated in a json structure. We can surmise that the way to do the ajax calls is with jquery, since jquery was included in the html you provided. Here is the jquery documentation. Read through that and try and adapt their examples. Just to simplify things for you you can focus on the $.ajax() method, as the other methods are just HTTP request type wrappers around $.ajax. The html page you provided needs some jquery code to: define the handler code you need that will submit the form data to submit_rating.php bind that handler to the submit button of the form define a function that takes the json results returned from submit_rating.php (which are the actual stored ratings) and using those to update the various places in the Dom where the relevant numbers are required. Doing that can also be done with jquery, which has various methods to select and then manipulate DOM elements. Currently there is no code to do these things, that you have presented. If you need to write that code yourself, then you now have a basic step by step guide as to what you need to do. It's also a pretty standard way of doing things, although jquery has fallen out of favor in recent years as javascript frameworks like vue and react have become popular. Neither of those frameworks are relevant to your code though. I will mention in closing, that it would be very helpful for you to understand submit_rating and it's dual purpose. That script is designed both to update the statistics if the review form was submitted, and to also get the statistics, and those 2 functions are not mutually exclusive. You must understand how to construct a POST structure in your function that is meant to handle a form submission, by getting the input from the field(s) needed and passing that in the post. Make sure you understand how to get that code to be triggered when the form is submitted, and not triggered when it's not needed (ie when it's just a GET request to load the page). Hope this helps you move forward.
-
You provided 2 "php" files, neither of which have any php code in them. I'm going to guess that there are scripts that the UI might call via ajax, to make changes to UI elements, but I don't see references to likely candidates in the html you provided.
-
I don't want to speak for Kicken, but I didn't interpret his reply as having any animus attached. It's not a personal attack, and I know he doesn't care whether or not you are a professional developer. He's been answering questions here for many years. Also, you are by definition a programmer, because you are programming He's just making the case that most libraries have a rigor to them that your code will not. In regards to efficiency, imagemagick and gd are written in c, so they are going to be many orders of magnitude more efficient than php code you might write to open a file and read it byte by byte. They both have literally millions of users using them, and they are part of countless websites, so they have been thoroughly tested, and in many cases, studied by researchers and students looking for bugs and exploits, which are all benefits of open source. I already expressed concern that a simple loop reading a file byte by byte is going to result in something very messy, because jpeg file structure isn't simple. The other issue, from my point of view, was also addressed by Kicken, which is that, data hidden in a jpeg file, in places where jpeg allows for data to be added, to his point does not weaponize the image, and is also valid. This is not unlike the way computer viruses work, and why antivirus companies exist. They must constantly identify new viruses, and fingerprint them, and this job is never complete, because virus writers keep changing them and finding new ways to hide them or exploit new vulnerabilities. Going further with this analogy, a big concern with images has been "stegosploits" where the payload is hidden in the actual image data. In this case it's a valid jpeg, so I don't think you will be able to detect any issues with image of those types. At any rate, I don't want to lose sight of what your actual problem(s) are at present. You can not have your cake and eat it too As you read through the file you can recognize the start of a structure You can continue to read until you get to the end of the structure Assuming you have now identified that structure, you can do analysis of it In all cases, aside from a simple scan to verify the existence of certain byte sequences, you will need to retain the structures in some form, if you intend to do further analysis of them. Preserving them, means that you will have to keep them in memory. I don't see any way around that, and again, I'd expect at very least to have functions or class structure to handle individual structures and do further analysis of them. I hope this helps, as beyond that, we are much better suited to specific problems than generalized/strategy based ones.
-
Namecheap is a company I have used in the past to get domains, and are trustworthy. They have a relatively low cost email hosting service. Zoho mail is also a reputable company with low cost email hosting. If you already make use of google services, then you might consider Google Workspace. Obviously, the company is reliable, and access to their entire business suite might be worth the extra cost. I don't know who hosts you or what you pay, but after factoring in the additional costs, it might be worth looking at an alternative hosting company that isn't taking things away from you at this juncture.
-
Just to be clear the getimagesize is mainly to prevent gigantic files you don't want to waste time rebuilding. You are absolutely correct that it can't be depended upon to detect a file with a hidden payload. That's why you have to rebuild the image from the stringified version of it using imagecreatefromstring. This of course does require enough memory to create the file, so there's no getting around that from a memory use standpoint.
-
Yeah, this seems to be a prefix towards an attempt to mass generate registrations for free gifts from this site. Locking it.
-
Also, this thread is probably interesting to consider....
-
I'm all for academic exercises for the benefit of learning. I think you will find this page of some help in continuing to explore the jpeg and jfif standards. However if your goal is simply to verify if an image is valid or not, that is problematic, because jfif allows for sections of a file to be ignored, so that special data could be placed there when the file is created. You could look at exif as essentially being this type of extension, so using the exif check functions is valuable in combination with other techniques. Exif data doesn't have to be there, but if you decide that you will only accept images that also have exif, then that is another valuable and efficient check, as you can use an exif checking function to exclude images that don't have valid exif data. In general, the proven method of knocking down malicious images is to use a combination of getimagesize and imagecreatefromstring, or the imagemagick routines kicken referenced. You used getimagesize to knock down files you have already decided are too large, and then recreate the image from file data. Either of these failing should cause rejection. Trying to go through the files and decipher them is most certainly a block operation where you would want to read the binary values, looking for the segments, and have routines that can decipher those individual segments. A simple loop is not going to be maintainable in my opinion. If I was trying to do this, I'd also want to try and see what gd and/or imagemagick source is doing, as those are both open source libraries written in c/c++. For example, imagemagick has a component used to identify the internals of an image. It's available in their command line tool that allows analysis and modification of an image. The source is here. A very large and complicated bit of code it seems.
-
In regards to prior code, while you should in general never interpolate variables directly into a sql statement and use prepared statements, in this case it doesn't matter because you are running md5 on both parameters, and it doesn't matter if someone tries to sql inject data, as the md5 function will convert the input and output an md5 string. This is one of very few cases where it doesn't matter what the input is. I'm not sure other than for testing why you are selecting the userkey. It's fine to have it in the criteria, but you wouldn't want or need that value to be returned in the result set.
-
Is this a new problem? I'm not sure what you are trying to debug here. You didn't use password_hash() to make the encrypted password so you don't need to use password_verify() to check it. You stated that you used md5() to encrypt the passwords. I'm not going to go into why md5 (especially without a salt) is not recommended, because that decision was made by someone in the past, and it is what it is. Your query is already checking for a name AND password match. Perhaps that was what you had previously (or something similar). I'm not sure why you thought that needed to be changed for php7. Even if there are things that weren't recommended security practices, you can't "upgrade" a security scheme by changing a few functions. In your case, all you need do is something like: function LogMeX2($name, $pwd1) { $sql = "SELECT User, UserKey FROM LIBusersX WHERE UserKey = '" . md5($pwd1) . "' AND UserN = '" . md5($name) . "'"; $pdo = connectDB(); $stmt = $pdo->prepare($sql); $stmt->execute(); if(!$row = $stmt->fetch()) { return false; } // username and password matched, return user id return $row['User']; }
-
You have to figure out where $pdo is being assigned. There must be some include or required where the database connection is initialized. Clearly there is already a $pdo variable being passed to that function.
-
Yes it is end of life. Obviously they are behind because PHP 5.6 (which was the last release in the PHP 5 branch) was end of life over 4 years ago. There was no PHP 6.
-
Aside from the interesting comments made by kicken and maxxd, it's hard to help you with a database problem when you provided us with no actual code that read from your database. I have a lot of questions, but it goes without saying that, if your css file is being generated dynamically with database variables interpolated, changing something in the database doesn't automagically cause the generated css file to change, nor will it make the source page reload, nor will it clear the browser cache of the css file. By default stylesheets will be cached, so it's common to have to use some sort of cache busting scheme to get around this behavior. For example, lets' asssume your script is named style.php. You might need the main html page to add a url parameter like: <link rel="stylesheet" href="style.php?v=something"> You could do something like generate a random string for the parameter like this: <link rel="stylesheet" href="style.php?v=<?= bin2hex(random_bytes(8)) ?>"> This would essentially defeat any caching of the css file, but also -- you get no css caching I'm not sure what your actual issue is, but this might be related to whatever you are experiencing, although you also may have database query and fetch issues we don't know about.
-
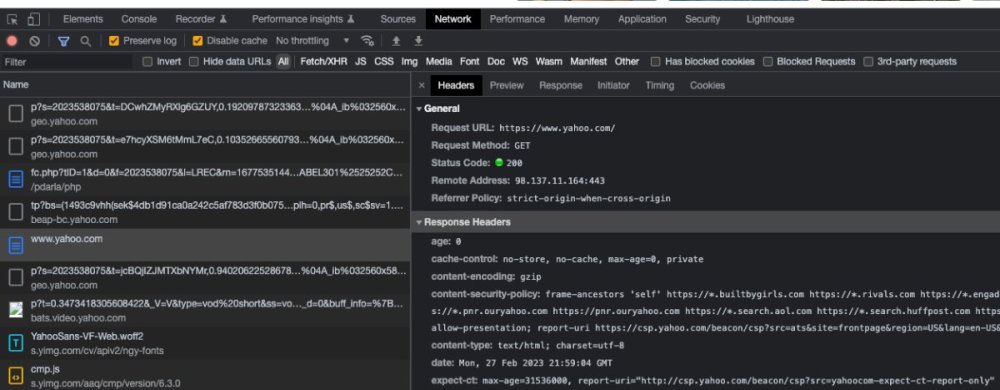
The point of the exit is, consider this pseudo code Do thing 1 Do thing 2 exit Do thing 3 Do thing 4 So with an exit, there is no way for execution to get to thing 3 and thing 4. The key thing that might help you understand, is where code is executing. This is difficult sometimes even for developers who are actually working in web development as kicken's story illustrates. In your case, "Do thing 2" is actually: set a browser header to tell the browser/client to redirect to a new html page. This is the way the HTTP protocol works. The user/client's browser makes a request, and the server sends a response. These request/response chains happen as rapidly as possible, and the underlying network connections are opened and closed as soon as the request and response are completed. The problem here, and the reason you NEED an exit, is because, it is entirely up to the browser to perform the redirect and reload. In other words, sending the redirect header in a response is the server "trusting" the client to do the right thing. So when you say it works, that is because in a typical scenario, the browser does make the redirect as requested. One of the many difficulties in web development is that the client can "never be trusted" to do what it is supposed to do. There are all sorts of methods and tools that people can use to emulate an HTTP client. In fact, serverside code will often emulate a client for the purposes of doing things like talking to API services or electronic payment gateways. People often also mistakenly think if they add javascript (which runs in the client browser) security and validation routines, then this secures a page, when in fact, these same tools can run pages without running javascript, and thus bypassing the javascript validation and security. Again, the rule of thumb is "client data can not be trusted". This is also the same area where SQL injection bugs catch people: because they accepted client data, and trusted that it was appropriate without validating it first. So to summarize, you won't see something different with an exit, because the client does its redirect as expected. However, without the exit, the script continues to run on the server until it completes. At best that's just some wasted execution time, but at worst it could be entry into entire sections of code you didn't expect it to. If you have a logging/debugging feature in your code, where you could log out messages, you could put a logging line directly after the redirect and you would see that it would log out a message, even though the header() function runs, and the client accepts that and redirects. One amazing tool that everyone has available to them, is the developer tools built into most of the major browsers. All of them have a network tab. Getting familiar with that tab is a huge help in understand how HTTP works and how your code works. Here's a screen shot of the developer tool window in chrome, open to the yahoo.com homepage. I've clicked on the main get request, showing what my browser sent as a request. From here I can look at the response, as well as all the subsequent requests that came from my browser once the html was delivered from the server. This is because all the individual components of the page (css, javascript, images, videos) are loaded separately from the html that references them. This excludes js and css that were embedded in the page, but rarely do people do that, and typically are making references to load those resources. This is an amazing tool that anyone who is doing any sort of development should use regularly during development. You can see here, the important HTTP elements: Request/Method (Get,Post, etc), status code. The server and port that the request was sent to. You also can see response headers here from the server. You could check the Cookies tab to see the cookies sent by the server, and the response data in the response tab, to see what the server sent in response. Once you get a real understanding of how the web actually works via HTTP, many things become clear.
-

get new value of type='date' field in its onchange event
gizmola replied to ginerjm's topic in Javascript Help
@ginerjm: Why? You are storing either a date or datetime in a database, right? If that is the case, then your extract certainly doesn't need to depend on a redundant database column, when your extract can just compute that during the process to send the data to the client. Perhaps we are also missing content on your environment. Right way: Server uses UTC Database uses UTC Always store datetime values as UTC Queries/display take into account client/enduser locale when presented. Yet it is not unusual to see people say: well I'm in albany, NY, so let me set up the system with the database to be based on the EST timezone, and then all the dates/datetimes will be what i want to see (in my local timezone). Unfortunately that creates a mess of potential confusion, and is not best practice, but if that's your reality, perhaps that is part of the underlying issue. -
It's great to get some context on your problem, but then you follow that up with a page of markup. So let's be clear about the database. If you have a bunch of tables that aren't relevant to this feature, that's not at issue. What I asked for is the tables that are relevant. The tables that effect login, and membership level and this "sale visibility flag" or whatever it is that you are trying to do here. What you provided previously is useless without context. id salecheck (varchar) This is a useless table, which can't possibly be useful, unless there is something else you haven't explained. If these are just columns in a user table, then I can tell you the structure of this feature is wrong, and will never be useful, but so far we haven't gotten to that point yet. I've been developing systems for a living for decades, for companies large and small in the entertainment, gaming and telcom industries, as well as a number of consumer startups. I tell you that your problem is likely in/related to the database structure (or lack thereof) and you say: Database is fine. I say: don't use a varchar to store a boolean, and you say that is too much trouble to change, when the fact is, not only is it not too much trouble, but could have been done and taken into account within 10 minutes tops. You say: I need a default value, so I don't have to set it, after I already stated, a flag should be a tinyint with default of 0 (ie. false). Of course it's not even clear now that a flag is what you need here, since it's not clear what the use case is. The difference between us, is that I have designed databases used in systems that served 100's of millions of people, and you haven't. This is not hyperbole, as I designed the underlying database used by one of the most successful multiplayer games ever, and that served 10's of millions of players and an untold number of games at this point. When we have people with problems like yours telling us how to help you, that never ends well. We've been helping people for over 20 years, so we know a thing or two about it. Just because you have an irrational fear of changing things in the database design, isn't going to change the fact that doing so, when you know what you are doing, as most of the developers who visit this site and help people do, it is not only not dangerous or problematic, but it is also much better than trying to add spaghetti code to work around the problem. We know what is hard or dangerous. When you describe your system, which as I understand it has: Members Levels of membership Companies Company Promotions And you have a feature where you want to be able to have company promotions/sales that are shown to members of a certain membership level, that is not a difficult design problem. It's a variation of what every site that offers affiliate links does (although very few have reason to secure this away from people.) If there is a wrinkle to this that isn't clear here, you'll have to forgive me, because this has been a process of peeling the onion, in order for us to get at what that problem actually is. You want to fix it, we want to help you, but you have to be willing to meet us halfway.
-
implementing polymorphism and inheritance
gizmola replied to bernardnthiwa's topic in PHP Coding Help
I assume you have a database behind this. How have you solved it with database design? Typically this would be "subtyping". So polymorphism is not involved. What is involved would be inheritance. But I'd start with your assumption here. You basically have a list of "Finished Goods". All of them have dimensions and weight. Is this academic, because your original supposition is arbitrary and incorrect? Rather, it seems that you want to associate one or more product categories or tags to the finished goods in this list. Let's assume you had a product_type table that included a primary key and a name. That table would have in it: 'Book', 'DVD', and 'Furniture' and likely many more. You'd classify the product by having a foreign key for this table in the product table. Now beyond this, there could be any of a million different facts that relate to a product. How do you think an ERP or Amazon solves this problem? Do you think they formulate a bunch of structure specifically for each type before it can be sold? One answer is: use properties. In the database consider how you might allow for One-to-many properties such that they could be assigned to a product. When you need something generic and extensible, you often have to design something generic and extensible. Another answer is to use a structure that is intrinsically hierarchical, like json, and allow each product to store data in json format. This can then alleviate the problem with the rigidity of relational databases, in cases where you might need some data that isn't always required, and also isn't always structured exactly the same way. Some databases have json types, and then there are "Document" databases like Mongodb, which is built upon a version of json, and essentially uses json as its internal structure. From document to document in a Mongodb collection, the json structure can vary. So you could have a basic structure, and then a section that completely varies by product type. -
Systems backed by a relational database are very often overlooked when people are inexperienced, and suprisingly, they are often overlooked by experienced developers as well. The reality is that the future of the system is tied to the decisions made when the database is first being designed. I like to use the analogy of saying: "people don't go and try and build a skyscraper on the foundation that laid for a one room mud hut" and yet that is what so often what happens. I would suggest we take a step back from what you perceive as your problem and take a look at your database. Proper database design takes a fraction of the time that it takes to write the code that will use that design, and yet, it is so often the case that developers are in a hurry to implement something quickly that they don't take any time to design the database properly, arguing that it can be refactored later (which it never is). What database engine are you using? I think it's mysql but I'm not sure What tables do you have What is the structure of these tables With an understanding of that, we can probably help you fix any mistakes you made, and converse effectively about how and what you might need to add. This will then lead to a better understanding of a specific functional problem you might be having.
-
Did you look at the code I posted? You also have a database involved apparently and yet there is no code you've shown that does anything with the database. If you're reading data from the database somewhere we don't know what that code looks like. It won't magically create session variables. Dont design something like "salecheck" in a database as a varchar(255) if all you want is a true/false yes/no. Assuming this is mysql, then use a tinyint defaulting to 0. Then when you want that to indicate true, you set it to 1.
-
In regards to your membership levels, that is something that also ought to have a function or class. Then for a page you could configure it at the top with something like: require_once('security_functions.php'); checkLogin(); checkSecurityLevel(); // If gets to here then they were logged in // And they were of a membership level allowing them to see the page In short, avoid writing spaghetti by breaking down individual things into functions or class methods. This will be DRY, and easier to understand, debug and maintain.
-
So this code redirects to nosale.php if the person has a session id and $_SESSION['salecheck'] === 'yes'. It seems you want the opposite. A couple of things: Login is login. You shouldn't have a situation where you check login state AND something else like this for a business rule. You should have generic "always run" code that checks for login state, and redirects them to the login page (for any pages that are meant to be secured. Typically you would put that code into a function or class, and include the function or class. Then you can have at the top of any secured page something like: <?php require_once('security_functions.php'); checkLogin(); // If gets to here then they were logged in // Do page specific things if (!$_SESSION['salecheck'] === true) { header("location: nosale.php"); exit; } Use PHP booleans in your session rather than a string. Nobody sees the session variables, other than your code. //Somewhere in your code $_SESSION['salecheck'] = true;
-
Now worries. Great to hear the community was helpful.
-
get new value of type='date' field in its onchange event
gizmola replied to ginerjm's topic in Javascript Help
It looks bad. It's the equivalent of someone having a calculation where they are adding 2+3 and getting 4, and deciding to "fix" that by adding 1 to it. Your examples all seem contrived and it's still not clear to me reading this thread, what the "why" is here, because you are manipulating, copying and re-creating variables in various ways, and yet you stated earlier all you care about is getting a "day". I'm not sure what that means. UTC exists for a reason. Locale conversions exist for a reason. I've had this conversation with other people in the past who seem to have the same complaint about this, but in general, it's a simple concept: your 2/25 is not necessarily my 2/25 depending on the timezone we live in. For that reason people synchronize their servers to UTC time zone, and store dates in utc. The built ins at the OS level across the board are based on UTC. It seems like you are choosing to ignore what both Barand and Kicken have been trying to teach you. Figure out if you have a UTC or a "locale specific (ie. your timezone)" datetime. If it's UTC, and you are making a copy, but you want that copy to be locale specific, make sure you are keeping that in mind.