gizmola
-
Posts
6,060 -
Joined
-
Last visited
-
Days Won
153
Everything posted by gizmola
-
It's a class that can be iterated with foreach. It is not an array, but it has many eloquent specific capabilities you can read about here: https://laravel.com/docs/9.x/eloquent-collections. For example it has a method that will return all the primary key values of all the models in the collection. Keep in mind that it extends the Laravel collection base class, which has many more methods that might be useful depending on what you want to do. See https://laravel.com/docs/9.x/collections
-
Seems like you ought to buy Barand a cup of coffee at least
-

I'd appreciate some feedback about my website design
gizmola replied to foxclone's topic in Website Critique
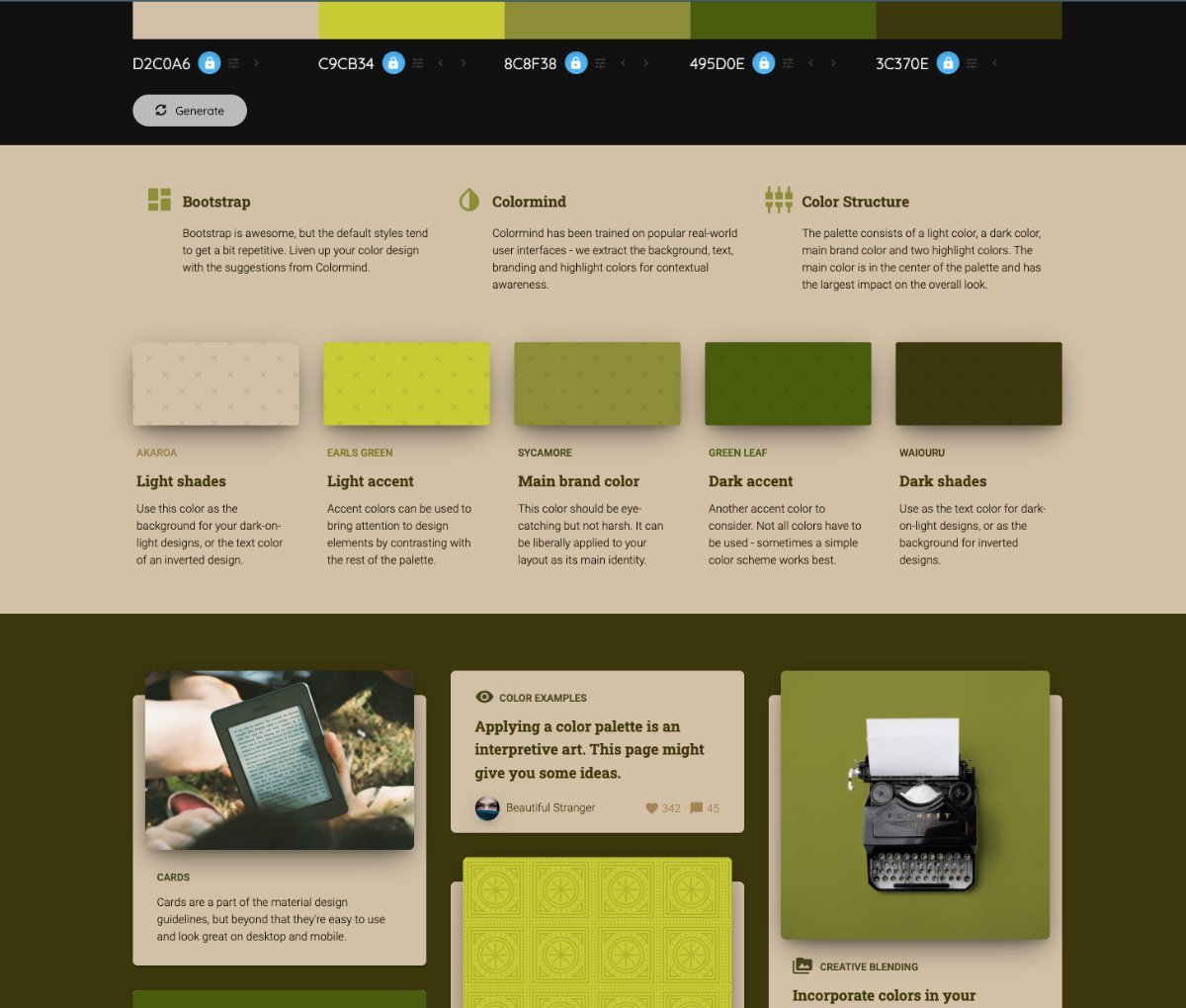
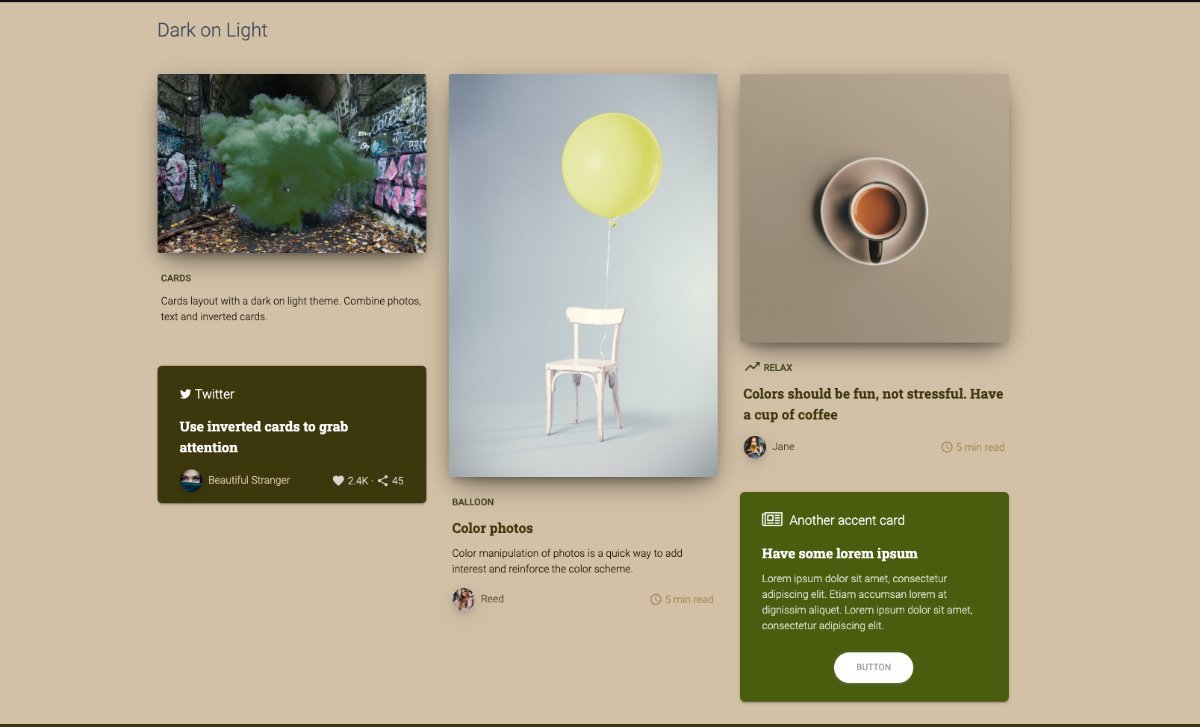
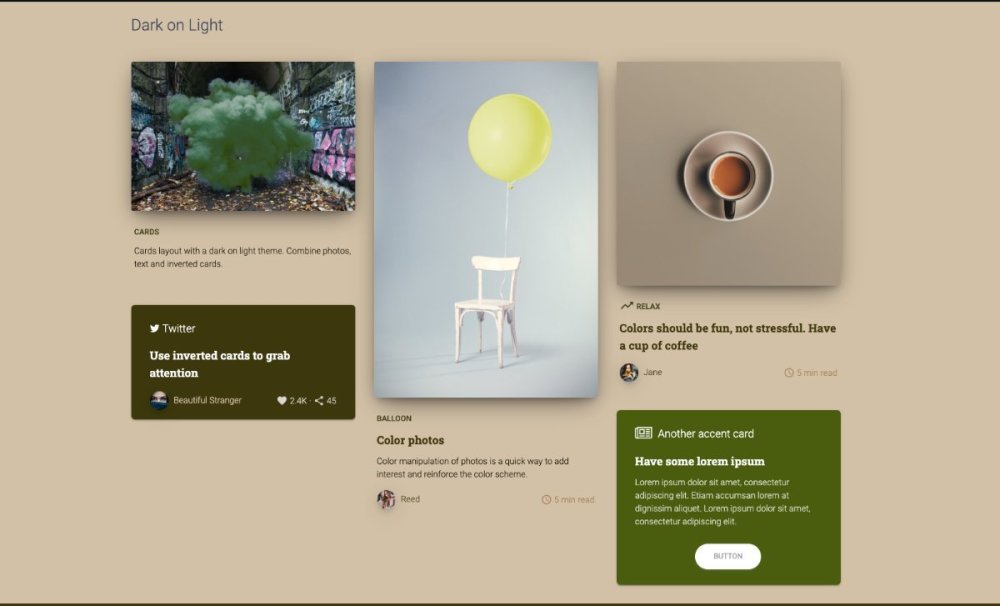
Yes definite improvement. Don't use any colors that aren't in your palette other than black or white, which are neutral and sometimes necessary for legibility and accessibility. The ugly yellow color that seems to persist in the menus needs to go. You have the option of making the top menu black with white or off-white lettering, or going with a color combo from your palette. I'd also suggest taking a look at fontawesome and trying to find some icons that you can use to accent your sections. The mockup has examples that should give you some ideas. You want to find an icon for each section that visually illustrates what the section text is saying. I extracted a palette from your image and applied it to colormind.io, which has a nice prototype screen showing you different ways the palette could be assembled. My advice would be to use some of the darker or lighter shades of the palette, and then use the green for your windows. The mockup here should help you get a better idea of what you like. The top is the color palette. You then have a summary, that also works to show you what a light overall background color for your site would look like. The next section is what a dark color background would look like. I would suggest you start with that. I also provided the "Dark on light" mockup. I'd suggest trying the "main brand color" #8c8f38 color for your menu and footer background.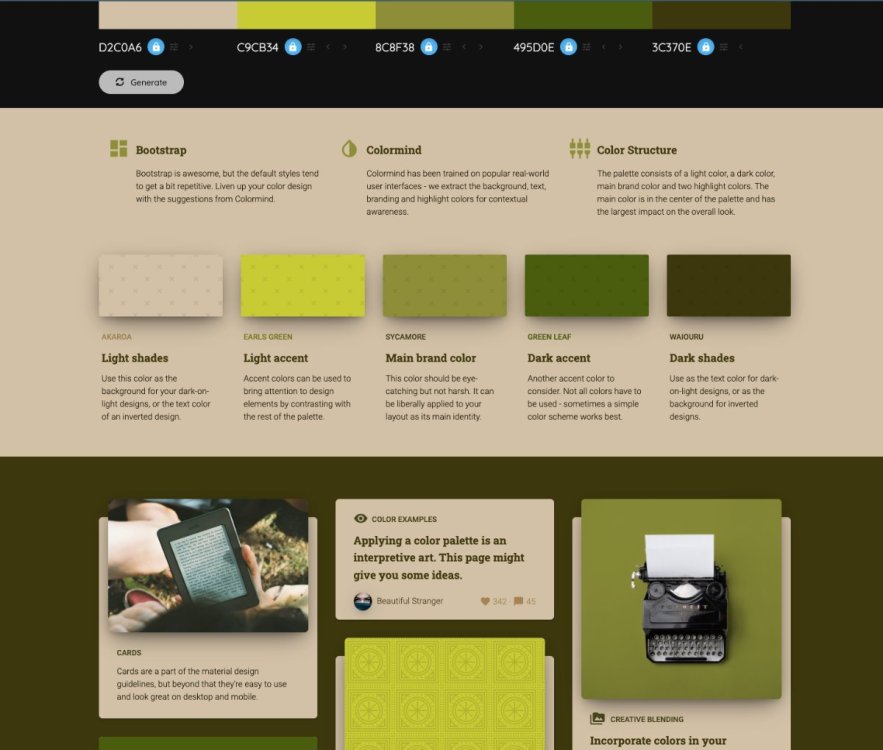
-
What you are doing is very confusing. Why are you not extending from the \PDF_Code128 class? Do you need the features of that class or not? Having code that both defines a class and also creates objects of that class is terrible. Have your class definition in a script with the name of the class as the name of the script. Then require that class in your script. As for the problem, it's shown to you clearly in the stack trace. You need to actually learn to look at it and follow it. FPDF is throwing the "No page has been added yet". You need to determine where in your code, that exception is occurring. The stack trace shows you that: $barcode = $pdf->Code128( 4,3,$data['item_code'],30,10); So this is the code that triggered your error -- and it's an object you try and create, purely so you can pass it into your class, yet don't even use in your code.
-
The plugin issue is just a theory. I have no experience with XenForo, so all I can offer is an educated guess. If the person had some sort of axe to grind with the forum, then I guess that could be the case, but I thought that you moved things to a new server, so perhaps there is a separate installation for plugins that needed to be done.
-
I don't see a url in that data.
-
I don't know if you have additional configuration you aren't showing us, but the mail server has to be configured to relay mail from your server. Outside of that, there are so many different things that could be causing the send to fail. Are you getting an Email failed message? As requinix stated, there is little to no visibility into SMTP using the mail() function in the way you are trying to use it. Phpmailer or Symfony mailer have ways to actually debug the internals of the SMTP process.
-
I'd appreciate some feedback about my website design
gizmola replied to foxclone's topic in Website Critique
This is moving in the right direction. Use a CSS reset. If you're not sure about how to approach that, while it might be a bit of an overkill for your project, normalize.css has been adopted by major css framework projects like bootstrap, so it will accomplish what you want. https://necolas.github.io/normalize.css/ In regards to your color palette, I think you need to either lean fully into the "warning sign" yellow on black of the menu and footer, or use something that goes with the light blue background of the panels. The colors do not go together at all. I'd suggest a color reboot. There are a couple ways you can go. First you can try out one of the numerous color palette generators to find a set of colors that are harmonious and utilize various color theory algorithms to generate the palette. One I like is Paletton: https://paletton.com/ It shows you a color wheel where you can choose from monochromatic, adjacent, triad and other schemes, and with a click or 2 include or exclude things like "complementary colors". There are also sites like css drive where you can start with an image, and let their software analyze the image to extract a palette for you. Here's one example, but there are others that might be as good or better: http://www.cssdrive.com/imagepalette/ I would also advocate making sure that you don't have odd alignment issues like you now do with the fox image. That should fill the entire panel, or at least be in the middle of the panel. There's really no reason not to have it fill the entire panel as you now have it. There's also that weird vertical line between the panels, that should go away, along with other things. If you make use of css variables, then you can recode your css so that it's easy to change the core colors you are using, which will allow you to try out a few different palettes quickly to see what ultimately looks the best to you. -
People will need to see the structure of $resp in order to help you. Also, please use the code button <> to paste your code into your posts.
-
I'd appreciate some feedback about my website design
gizmola replied to foxclone's topic in Website Critique
The site just has a dated feel to it, that could use a good freshening. The real sign of professional design starts with consistency and each of your pages has something that's a little bit different, which undermines the consistency. While I like the fox picture, I would make that more of a hero image or something at the top of the page, that then combines the other pages via scroll. A visitor shouldn't have to investigate your menus in order to find out what the product actually is, or why you should care about it. The buttons on the download page look like something you would find on an early 90's ebay page. The first thing you should do is replace those with some decent markup, css and button code that has hover effects. -
There seems to be a problem for some number of people, typically having to do with local OS/Network/DNS/IPv6 settings. You can see if any of the suggestions here are helpful to you: https://github.com/composer/composer/issues/9376 You can run composer diagnose to have composer go through a battery of tests that might help you see where your issue is.
-
Changing text displayed at end of countdown in timer script
gizmola replied to foxclone's topic in Javascript Help
Nice job foxclone. A few notes: My main suggestion for you is to replace your use of var with the appropriate let and const keywords, as that is the current (ES6) way to declare variables. People don't use var anymore for reasons you can explore more fully yourself. If a variable is a base javascript type that is not an object, and that value won't change, then use const. Also use const if it is an object (in most cases). Otherwise use let. One other thing that is a good practice to get into, is to not use ';' as javascript doesn't require a semi-colon to end a statement. Trying to avoid using semi-colons will make your javascript more concise and help remind you of the syntactical differences between php and js, when you are switching back and forth between them. When you consider your code, the check for timeleft <= 0 will be true when your counter is == to 0, so there is no reason to have a separate condition check for that. Do both things you need to do (clearInterval, update your paragraph to 'done') within that same condition Here's a refactor for you, implementing all the comments above--- let timeleft = 10 const downloadTimer = setInterval(function() { timeleft-- document.getElementById("countdowntimer").textContent = timeleft if (timeleft <= 0) { clearInterval(downloadTimer) document.getElementById("test").textContent = "Update Complete" } }, 1000) downloadTimer() -
There are a few concepts that will help you. The first is the use of the empty function. For arrays it is especially useful, in that it checks both for existence and whether or not the item actually has a value. While you can foreach() an empty array, with empty your code can already detect that the array is empty and the foreach will never be entered. This revised code should help you better understand the variations in the data: if (!empty($inventories['rgDescriptions'])) { foreach ($inventories['rgDescriptions'] as $key => $description) { if (!empty($description['descriptions'])) { foreach ($description['descriptions'] as $key => $effects2) { var_dump($effects2); } } } } This reveals that app_data is an array that exists in some entries, and when it does, appears to have key/value pairs. array(3) { ["value"]=> string(15) " Death Stare" ["color"]=> string(6) "4b69ff" ["app_data"]=> array(1) { ["def_index"]=> string(5) "31225" } } array(3) { ["value"]=> string(24) " Spooky Head-Bouncers" ["color"]=> string(6) "4b69ff" ["app_data"]=> array(1) { ["def_index"]=> string(5) "31209" } } A useful function for finding out if an array has a particular key is array_key_exists. This helps you determine if the app_data array contains a 'def_index' value or not. There are many entries in your data that don't have one. Putting this all together, I added code to output the item 'value' which appears to be a name, and the def_index value you wanted. I don't have any idea what that value actually is, so I included the name to make this demonstration somewhat interesting. Frequently the name has whitespace in it, so I used trim() to remove that. if (!empty($inventories['rgDescriptions'])) { foreach ($inventories['rgDescriptions'] as $key => $description) { if (!empty($description['descriptions'])) { foreach ($description['descriptions'] as $key => $effects2) { // var_dump($effects2); if (!empty($effects2['value']) && !empty($effects2['app_data'])) { if (array_key_exists('def_index', $effects2['app_data'])) { echo trim($effects2['value']) . ": {$effects2['app_data']['def_index']}" . PHP_EOL; } } } } } } Oh Deer!: 31245 Jolly Jester: 31243 Merry Cone: 31247 Hat Chocolate: 31259 Elf-Made Bandanna: 31260 Seasonal Spring: 31244 Elf Ignition: 31253 Train Of Thought: 31254 Seasonal Employee: 31258 ....
-
I can't figure out what i'm doing wrong for the life of me (PHP/SMTP)
gizmola replied to emcuriah's topic in PHP Coding Help
Almost forgot to say that I edited your original post because it appeared to contain your actual gmail password. I would change your gmail password ASAP if it actually was the real one. -
I can't figure out what i'm doing wrong for the life of me (PHP/SMTP)
gizmola replied to emcuriah's topic in PHP Coding Help
These type of contact pages don't work very well for a number of reasons, most notably that bots fill your inbox with spam. This particular script can also be exploited by anyone (and again mostly it will be bots) to send email from your account, via this line: $mail->addAddress($mail_from_email, $mail_from_name); // Add a recipient I can spam your form, put a bunch of porn site links in the body, and have my from address be some person I want to spam with those links, and your gmail will send them a copy of the email. That line should be commented out at very least. As Req already noted, we need some debugging information, because we have no idea at what point where the script fails. -
It seems very likely that it is a missing plugin that handled message attachments.
-
Telnet response does not output all data (using PHPTelnet Class)
gizmola replied to jaybo's topic in PHP Coding Help
Maybe try a newer telnet client library like: https://github.com/graze/telnet-client -
So we have established that my suspicion was correct. You have a problem with a commercial product that we have no way of looking at. It does seem that this is related to an "attachment" processing addon, but I could also be wrong about that. Either way, without the actual source, or access to your server, there isn't some magical generic fix that is going to make things work. The stack dump you attached should be looked at in reverse. So the first item was the last method run. It was running the getEditorData() method in the Attachment class, and something the code is doing at around line 1752 triggered the exception. The message indicates that there is a "handler" architecture involved, and whatever is being read has the "post" content type, which is likely some internal classification of data inside the application/database. The code is expecting there to be a handler (ie. some code that will be able to figure out what to do next) and the forum software is not finding any handler that's been registered within the application to be able to process further, so it throws the exception and exits. This is why I suspect that the old forum might have been using some sort of plugin, and possibly your issue is that you don't have that plugin installed and configured with whatever Xenforo installation you have now. Also as I stated in my prior message, the forum version and PHP version you are running could very well be at the heart of the problem, as it's possible if you are running an older version of their forum software, that there are techniques and syntax that don't work anymore with a more current version of PHP, or as I surmised, there could also be a plugin missing. I don't think there's anything more I can suggest for you, other than to seek help on the xenforo and Xfrocks communities. I hope this helps you
-
You have a couple of issues -- one cosmetic, and one functional. The functional issue is that your data- keys are incorrect. You need data-bs-toggle and data-bs-target. You also don't have the nav inside a container which makes it wonky, although that is not why the hamburger doesn't work. Fixing both of those gives you this (just the body section). <nav class="navbar navbar-expand-lg navbar-dark bg-dark"> <div class="container-fluid"> <a class="navbar-brand" href="#">Test Nav</a> <button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarNavAltMarkup" aria-controls="navbarNavAltMarkup" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarNavAltMarkup"> <div class="navbar-nav"> <a class="nav-item nav-link" href="login_create.php">Create</a> <a class="nav-item nav-link" href="login_read.php">Read</a> <a class="nav-item nav-link" href="login_update.php">Update</a> <a class="nav-item nav-link" href="login_delete.php">Delete</a> </div> </div> </div> </nav>
-
One more thing that might help: It looks like it may be possible that the issue is related to the use of XFrocks, which is some sort of commercial addon to Xenforo.
-
Educated guess: Xenforo? From what I can see it's a commercial closed source product. It seems a day doesn't go by where I find out about some php based product I've never heard of, that has a business built around it. If my suspicion is correct, there is very little help anyone here can offer, as it is unlikely anyone has any experience with it. My best advice would be to find an experienced PHP dev, and probably one who has familiarity with Xenforo. Your best chance of finding such a person, whether it be free advice or someone you can pay to help you figure out your issue, is going to be on the Xenforo Community forums. As requinix already stated, if it is not xenforo, the first thing we need to know is what forum software you are using. Be candid and provide details if you want further help. Things like the os of the server, version of php, and version of the software being run are important.
-
convert GET to POST (and AVOID $_SESSIONS !!! )
gizmola replied to ChenXiu's topic in PHP Coding Help
Now that you have clarified, when there is a link to your site, and you click on that link in another tab, it is going to open a new tab, because it is a separate request. It is not going to override your existing session. If your goal is to make the work in progress in the first session visible to this new session, then you should 100% stick with using sessions. It is the only way you will provide a good experience across instances. I would also pair that with ajax, so when people add an item to the cart, you don't require a submit. The important thing is that during the ajax call you will store the state of the cart in your $_SESSION. That way, any new browser session will have the current state of the cart. Utilize your form post purely for the finalized submission of the cart. -
convert GET to POST (and AVOID $_SESSIONS !!! )
gizmola replied to ChenXiu's topic in PHP Coding Help
In most UI's all of this would be done with ajax. You have your UI visible and user enters an sku (ajax call runs), no submit necessary. User clicks a delete/remove button for an item, that would also be pure javascript (DOM manipulation) I would only have a traditional form submit for the finalized/order process. The more you describe these links the more it sounds like it could be handled purely by javascript. Write some javascript to handle the onclick for your links so it opens a new tab/window. You can try to use a "popup" but many people have popup blockers installed. Another option as I mentioned, would be to use a frameset, and have a hidden iframe that you load those linked sites into and display. Either way, it shouldn't interfere with the processing of your site. Last but not least, sessions are just a feature of the php server. They don't require login (but I have to think you knew that because you were already using them). If you don't like the idea of a block of 15 lines of code or several blocks, that's not unusual. Put them into a few functions. This is really what I meant in regards to structure. Breaking things down into functional units is the best way to start to eliminate any confusing logic concerns or reliability problems. This also makes creating unit tests even more viable. Writing a couple of unit tests for a couple of functions is not a big investment of time, and would go a long way towards giving you a comfort level in regards to your system. Even if that's beyond your current level of capability, writing functions surely isn't, and of course makes those functions reusable. At this point, we would really need to see some code from you to provide much more of value. -
convert GET to POST (and AVOID $_SESSIONS !!! )
gizmola replied to ChenXiu's topic in PHP Coding Help
There's a lot to unpack in your question, so I'll try and address a few things. As Barand already suggested, Ajax is the standard solution to this problem. Another possibility would be to use frames and have the lookup occur in an iframe. Without seeing your UI It's hard to understand the modality issue or possible solutions to it. This sounds like a "you" problem. Using sessions does not require 1k lines of code or anything close to it. If you have structure issues or something that doesn't work correctly, that probably relates to the structure (or lack thereof) in your code. One other issue that does sometimes crop up with manual regression testing, is that you can get into a situation where you are doing things that a normal user will never do, because you are repeatedly testing things with your browser which engages your local environment, making a session cookie and one or more sessions on the server. Unit tests and automated testing tools are valuable in separating things, because they offer a fresh client environment and repeatability. With unit tests, you avoid environmental issues entirely. If you are only able to do manual regression testing at this point, one suggestion I would make is that whenever you are doing testing, engage Incognito mode for that testing session and exit it when you're done. From a usability point of view sessions offer a feature that you can't get with pure HTTP GET/POST, and that is server side storage of values that is both "secret" and persists as long as you want it to persist. If someone accidently closes the browser or tab entirely, everything will be lost, whereas with sessions, they can get back exactly to the place they were. So beyond the out-of-band issue you currently face, sessions can facilitate many usability features that can only otherwise be handled in any form with some combination of cookies and POST/GET variables. Of course Sessions do rely upon a session cookie, but that should be, once configured, completely invisible to you, whereas direct cookie handling requires a detailed understanding of HTTP and how/when cookies can be set. -
Most decent editors show you syntax errors as you edit. What are you using? You can also use your command line php with -l for linting. php -l /path/to/script.php