gizmola
-
Posts
6,100 -
Joined
-
Last visited
-
Days Won
158
Everything posted by gizmola
-

Could use some insight on a database installation issue...
gizmola replied to Jim R's topic in MySQL Help
We don't have enough information to really help you here. Looking into xenforo, I see that it is a commercial product, with a self host license of $195, and no open source version. Without the source people really can't do any debugging for you. My advice would be to contact the company directly as this is some sort of installation issue, and they are really the only ones in a position to understand the implications of that stack trace. -
I'd suggest you try to use php://output directly. $stdout = fopen('php://output','w'); foreach($rows as $row) { fputcsv($stdout, $row); } fflush($stdout); If for some reason this doesn't work (or work reliably) with your host, then I'd suggest writing the data to a file with a temporary name you create using some random input and something like sha1, and then open that file and send it back to the user, but sending it directly to output is a standard solution for this type of requirement.
-
We get this type of question all the time. Our purpose is to provide a place to mentor and teach people who are genuinely trying to create systems and learn and improve. Everyone has to start somewhere. With that said, it doesn't seem as though the thing you started with is very well designed or suitable to what you are trying to do, but then again we don't really know the details of what you've agreed to provide for your friend or on what timeline. Creating an online reservation system is a non-trivial exercise by itself. OpenTable's cost for their most basic tier of that service is $149/month, so that should tell you something. As a beginner, that is certainly biting off more than you should be in my opinion. The problem with doing something ill conceived or broken equates to literally lost revenue for the restaurant. Let's say that it doesn't work right and people attempt to make reservations and the system doesn't allow them to, or erroneously shows that a reservation can't be made, or double books, or overbooks etc. The result will be people who wanted to come to the restaurant instead going somewhere else. Operationally, the restaurant staff has to be able to (and will be required to) interact with the system throughout the hours of operation. It is no small task, and yet you are approaching this in a way that suggests little thought was invested into this project. Personally, I'd take that right off the table, as just handling the online menu and ordering is already a large job. This also will involve payments and interaction with a payment gateway. Anything less than that, and there is going to be manual entry of things, and storage of credit card data that you aren't legally allowed to perform. So, yes I would agree that you have greatly underestimated this task. From the discussion of this so far, you did not even acknowledge my comments regarding making a lunch_menu and dinner_menu table, which I already told you was a mistake. You thought this was a good idea because you saw that you needed 2 "types" of menus right now. ('dinner', 'lunch'). Let's continue this line of thinking then, and apply it to a menu item. I'm sure that menu items have different categories like ('appetizer', 'beverage', 'main course', 'dessert') etc. So that must mean that you will have at least 4 new tables right? menu_item_appetizer, menu_item_beverage .... etc., right? And that would be a disaster for your project! Here's the reality: any database driven (database connected) system is only as good as the underlying database structure. That is where you should start. Rushing to build out screens and write/modify code and create sql query strings is the wrong way to do this. The analogy I like to use for any rdbms based system is that the database design is like the blueprint for a building, that then becomes the basic structure. If you provide a blueprint for ranch home, you can't then decide later that you really wanted a 3 floor apartment building, and think you're going to have success adding that on top of your existing ranch home. You take the time to have a blueprint for an apartment building. You need a verified and validated database structure 1st. I will say again to be clear: if you need help with your database design (which is clear to me) then you need to provide us the current database structure so we can examine and advise you ASAP. Changes to database structure can be accomplished quickly, but the time to do that is at the start of the project, not after you've written a bunch of code which you will need to change. Sometimes you do need to make adjustments or improvements to the database structure once you are well into development, but you should have, to the best of your ability a structure that supports your needs from the outset, and you probably don't have that now, and have demonstrated you don't understand database design well enough to try and do this on your own without some experienced people advising you.
-
So your first idea was to make a non-relational goof up. You have a menus table and that should support any and all menus, especially if menu relates to other things. Simply adding a menu_type attribute in menus would have let you designate one from the other and to have other menus (like a happy hour, or thanksgiving, etc) as needed in the future. You literally did what any DBA would tell you not to. You should go back to the drawing board on that. This comes from the database, not from code. In other words, it is data related. You are trying to insert or change data somewhere in the system, which is not in the code you attached, as was already noted by mac in his reply to you. Just looking at that code mac provided a lot of excellent code quality and best practice suggestions, but it doesn't address the disconnect between what you seem to understand or not about your database and how constraints work and what they do. Apparently there is a foreign key constraint on the thaicook3.in_order column, which requires that any value added to the in_order column, must be a menu_id that exists in the menus table. The very names of this table (thaicook3) tells me a lot about how ill conceived this system must be. Having a non-relational schema in a relational database is the road to system ruin. We have a lot of veteran developers that visit phpfreaks who are quite willing to advise and mentor people on how to come up with a proper relational design, that will be easy to use, and allow for a flexible "data driven" system. Scanning the code you did provide, just having queries that contain things like WHERE id <> 9 is one of many examples of things that have been done due to lack of good design, and coding practices. Even if you were to argue that row id 9 in a table is "special" for some reason, you should have that in a constant or at least a boostrapped variable rather than hard coding the magic ID # into queries. There are much better ways (adding columns for example) to allow the system to determine if a row has a special property that should include/exclude it. If your goal is to produce a buggy spaghetti system, then continue on as you are, or you can take the time to socialize the database design with an ERD or even a database dump of the structure, and follow up with some basic requirements.
-
I'm not clear on what account you have an issue with. In general, if it's anything you really care about, then take the time to set up 2 factor authentication. Emails that claim your account is locked and prompt you to re-authenticate are often Phishing attacks, where you never actually hit the site you thought it was, and for that reason, any emails like that should be ignored, not clicked on. You might want to inspect the original email and see if it was forged. Looking at the email headers and the src of any links usually tells you the story there. Pretty much all sites have now gone to informational messages if they detect changes to an account, or unusual activity. They never prompt you to "login" or to click some link. Email is unfortunately untrustworthy and all emails needs to be viewed with suspicion.
-
Going insane. Ajax call sets session as expected but does not persist.
gizmola replied to jtorral's topic in PHP Coding Help
I am 100% in agreement with @jodunno on this. Media Queries is the right way to handle your problem. He provided some great links to look at. I understand that working with old code bases can be challenging. One way to work your way into it is to use a sandbox like codepen or jsfiddle and make a small proof of concept version that has a subset of the overall css and some markup, and just addresses the things you want to change in the UI. Chrome dev tools have a built in way of setting the client dimensions of the browser, to simulate a particular screen size, and there are also some extensions that do the same thing and make it a little simpler. When you first open the developer tools in chrome (using inspect) the first 2 icons let you turn on/off the device toolbar. With it on, you can set the dimesions so it simulates the dimensions of a device or you can manually set the dimensions. Then move those changes over into the new code. Hopefully it wasn't a huge mess of 100 scripts with the html markup copy/pasted everywhere, but even in a case like that, you can add a header.php and footer.php and start require_once() as you remove all the duplicate code. Last but not least, this is why a lot of css frameworks going back to bootstrap got popular fast, as they alll for the most part provide support for making your markup responsive.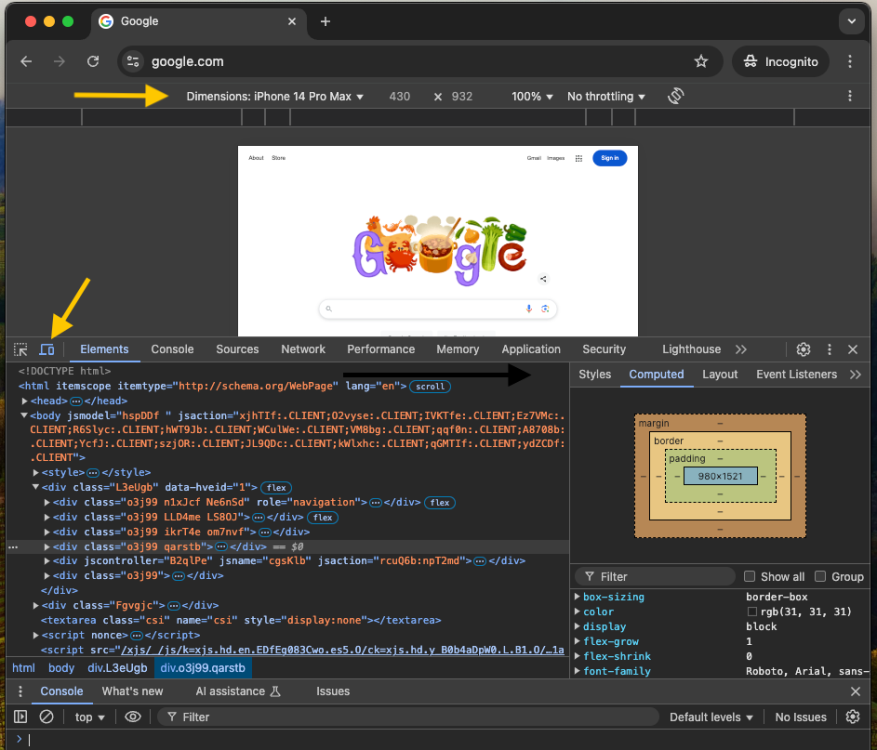
-
Going insane. Ajax call sets session as expected but does not persist.
gizmola replied to jtorral's topic in PHP Coding Help
Basically what is being described to you is a race condition. You aren't going to be able to hack around it. A PHP script runs on the server, and has "page/request" scope. The client provide an HTTP request, and the server provides an HTTP response, and the connection is closed. Ajax is used to make changes to the state of a fully rendered DOM on the client. You are not going to be able to trick PHP into doing some of its work -- delaying while the client's DOM is in a partial/indeterminate state, in order for ajax to spawn another request, and then have the original PHP script resume in the way you hope it will, all so that you can get access to session variables that didn't even exist when the original HTTP request was made. I have no idea why you are trying to store some client state in a session, given that browser dimensions are dynamic, relative to the device and decisions made by the client. It's not clear what you expect to do with these dimensions, which you're getting from javascript code, but you certainly don't need to put them into a session, and you haven't made an attempt to explain what problem you are trying to solve, but this is not the way to solve whatever problem that is. If you want to actually take the time to explain the "problem to be solved" we might be able to better advise you on ways to solve it. -
Correct.
-
No. In the code I provided I loop through your array and get each name attribute, then call document.getElementsByName(). As I mentioned what you get back is a nodeList. This is because when you call GetElementsByName the result can be 0 or more nodes, as you are able to use the same name attribute for any number of html elements. In this case, even though that is true, it's your markup and we know that there should only be one node found, and that will be the input that matches the name you passed. As arrays are zero based, item[0] will be the first (and since you control the markup) only element in the nodelist. You can think of it as an array that has only one element in it. As to what you came up with, using eval() should be avoided, as it's highly dangerous to the end user, should there be any possibility that someone can inject a string containing javascript into the string. You continue to attempt to reference part of the DOM document this way, when you already were presented 2 ways NOT to do that, either of which will work. As we don't know the actual form of these numbers that you require for input, we can't really advise you. isNaN by itself is not going to do what you stated you want to do. Here's a couple of examples: let foo = ''; let bar = '0xFF'; isNaN(foo); isNaN(bar); A quick test of these should be of concern to you. If the numbers entered must be integers then mac's Number.parseInt() might lead you to a robust and simple solution. An alternative is to utilize javascript's regular expression syntax. You might also try typecasting values. One thing to keep in mind here, is that in doing what you are doing, as you manipulate these values, you are creating new variables, but the original input values will still be in text form, so even if the data passes through your form validation, the values may be problematic at the point you store them in a database or whatever the app does.
-
I'm sure he does know that, and we are both motivated by an interest in mentoring and passing along our expertise to people like yourself if we are able. We appreciate the feedback.
-
I was going to suggest something similar to mac's post, however, I think a better UI choice would be to use AddEventListener to all the fields for the change event using getElementsByClassName to find them. There's an awful lot wrong with what you have so far, not to mention that you have yet to come up with any code that determines if a text input is actually a numeric value. It is deceptively complicated and non-trivial to do so, but that issue aside, what you were asking about could be remedied using code like this. One thing I noted is that you are trying to make a lot of global variables for no particular reason. Try to get in the habit of making as few variables as possible, and use ES6 let and const rather than var (which makes a global variable). What you were missing is the DOM method document.getElementsByName. It returns a nodelist, so make sure you investigate that. I did not try and provide you a solution to your stated goal, but rather, something that moves your work in progress forward, and omits issues with the pattern you are missing. Using this as a form validation means you can't return true for any individual element, but only return true when all elements successfully validate. So you do that by falling through to a return true at the end of the loop. There are several problems even with this code, but hopefully it helps move you forward from where you started. const arrayone= ["it_c","it_h","ot_c","ot_h"]; function hasNumericValue(arr) { // check for numeric values posted in the array of the input fields for (let i = 0; i < arr.length; i++) { let item = document.getElementsByName(arr[i]); let linker = item[0].value alert("Checking Field: " + arr[i]); if (linker == 10) { alert("Value was 10"); } else { return false; } } return true; }
-
Yes this is common practice. When you first introduce a table you can alias it. You are then free to alias all the columns which can be quite a time saver when you have joined tables together, using "alias.column_name" as Barand did. You can do this explicitly using the 'AS' keyword but you can also omit the 'AS'. It's up to you, but I typically will abbreviate the name in some way, as do most experienced developers, such that your alias is at most a few letters. You should also notice, that he used an alias for the computed columns. Column names can also be aliased, and it's also a common practice. FROM_UNIXTIME(t.time) AS time So in this case you have an example of both alias options being used: thread table was aliased to t Used the t alias to specify the time thread.time field being passed to the FROM_UNIXTIME() SQL function the result of the function being aliased to the name 'time' in the final result set Also time was used in the order by. MySQL allows you to do this (use an aliased column name in an ORDER BY) although not all RDBMS do.
-
Barry is truly a master of relational database design, implementation and SQL. However , at least initially, a small investment on your part in learning how to join tables together, will dramatically improve your understanding of his analysis and the SELECT statement he provided you. I browsed this material and it's a solid free tutorial on Joins using MySQL. https://www.mysqltutorial.org/mysql-basics/mysql-join/ You may see references to ANSI standard SQL, which is a standard for portable SQL syntax that should be compatible with most relational databases, but I did want to mention that different databases will have features that are specific to their implementation (non-standard), so you might see that in the case of joins there is more than one syntax possible, but they all do the same things. Don't let that confuse you -- JOINS are an essential concept that all relational databases implement. If you have an option, and can use ANSI standard syntax, opt for that, but it really doesn't matter that much, so long as you are clear on what the join produces. A basic understanding of Set theory might give you some insight into the ideas that went into relational database management (union, intersection, difference, subset) might help as well. This article cover the topic pretty well, and you may notice some of the overlap in concept and terminology: https://kyleshevlin.com/set-theory/ It's also worth learning how to read an Entity-Relationship-Diagram (ERD). Once you understand the fundamentals, you should be able to look at an ERD and understand how tables can be joined together. There are also many tools that people use to design or reverse engineer databases. For example, mysql provides ERD design features in their free SQL Workbench tool. ERD's are the way that people socialize a database design, and are the documentation that teams use to document for developers, the database design.
-
No problem, if we thought it should be moved we would have moved it previously. Glad we were able to help you out.
-
The first thing you need to be clear about is what a literal string is vs. an interpolated string. As this is an important fundamental, I'll assume you know which is which in the following examples. A key can be any sort of valid PHP string. So this makes it possible to get yourself into a lot of trouble potentially. One caveat, as you will see, is that even if you specify a literal string, if PHP determines that string is equivalent to an integer value, it will create an array element indexed by the value. So you can't have an array key of $r['3'] and $r[3]. Also, you should notice that it will cast a float to an integer, and that this behavior is deprecated, so clearly you don't want to ever try and use a float as a key, even though it will actually work (sort of), in that it converts the float to an integer. <?php $foo = 'bar'; $s = array(); // Anything that looks like an integer, PHP will convert to a numeric key $s["0"] = 'Apple'; $s['1'] = 'Banana'; // Notice it casts the flaat to an int and gets 2 $s[2.85] = 22.072; // However if they are strings, you can key on floating point values $s['2.85'] = 2.85; $s["2.86"] = 2.86; $s['$foo'] = 'literal'; $s["This is $foo"] = 'interpolated'; $s['.foo.bar'] = 'dot foo dot bar'; $s["\u{1CC0}"] = 'unicode'; var_dump($s); Here's the var_dump result: Deprecated: Implicit conversion from float 2.85 to int loses precision in php-wasm run script on line 10 array(9) { [0]=> string(5) "Apple" [1]=> string(6) "Banana" [2]=> float(22.072) ["2.85"]=> float(2.85) ["2.86"]=> float(2.86) ["$foo"]=> string(7) "literal" ["This is bar"]=> string(12) "interpolated" [".foo.bar"]=> string(15) "dot foo dot bar" ["᳀"]=> string(7) "unicode" }
-
If the php.exe executable is in your windows path, you probably won't have to manually add the path to that configuration. In fact you would likely need to delete the value from vscode. 1st to understand what the path environment variable does. When you try and run a program, windows will look for that program in the current directory. If it is not found, then it tries to find it in the path. So by design the path variable should have directories in it, NOT the full pathname to the program. So in your example the path you want to add is: C:\laragon\bin\php\php-8.4.3-Win32-vs17 x64\ Follow these instructions to add the location of your laragon php directory file to your system path: These directions were for Windows 10, but they also work for Windows 11. Make sure you don't overwrite your current path, but instead just edit it by adding the path to your php8x installation. Let us know if that fixes the problem. Make sure you restart Vscode after you have added the laragon path to your windows path variable.
-
Yes. It wants a local copy of PHP on your workstation. I do have to point out that PHP 7.4 was end of life 2 years ago now. It would be best if you upgraded to a more current supported version of PHP ( > 8.1 at this point in time).
-
You are starting with File1 and you diff it using FIle2. What do you get? You get a Diff file telling you how to change File1 into FIle2. The use case for diff-ing was as a tool for "authors" (in the olden times when diffs were commonly used to distribute updates to text based files) to provide patch files to "end users" who would use a patching tool to transform their files into the "patched" state. In the modern era, there are just better more reliable and resilient ways of distributing updates. Clearly, in this case the xml diff file shows exactly what would be expected when you give it a diff that is based on a file that has nothing but a new element. It deletes the original element, adds the new one, and leaves you with ..... file2. It's hard to say whether or not this is worth doing, even if it works, given this is sample data, however, you might try reversing the order of the parameters -- create a diff where you: $diff = $dom->diff($x2Doc, $x1Doc); I am not sure how it will resolve the 2 different attributes, but at least in this case, I suspect that it might generate the ultimate result you expect.
-
Since you have no PHP code, I have to conclude that this is not a PHP question. You are also apparently using Dropzone.js (or at least that is an educated guess), so I'm moving this to the right area of the site for javascript questions.
-
You are certainly not showing us the actual code you are using, or there is something in your debugging because sizeof/count returns an int. So the sizeof is not echoing 154[]. Something is echoing 154 and then something else is echoing out the "[]" which is an empty array. One thought I had is that this issue could have something to do with your query(s) and what is in your database. A common mistake (and one you are making here) is to assume you will be getting one row in a result set, and then fetching that result with fetchAll. If you only expect one row, then the query should reflect that, as well as the code you use to fetch the row(s) from the result. It occurred to me, that you might be getting what is essentially an empty row in your result set, or getting 2 rows when you only expected one. I can't say for sure that this is the issue, but it's a possibility, given the snippets of code you've provided so far. Your query is doing a lot of joins, and any confusion on your part or extra rows in the joined tables will generate additional rows in the result set as a product of the join.
-
Here you go: $json = '[ { "place_id": 329211526, "licence": "Data © OpenStreetMap contributors, ODbL 1.0. https://osm.org/copyright", "osm_type": "way", "osm_id": 19239538, "boundingbox": [ "34.6786854", "34.6787122", "-77.5843465", "-77.5835107" ], "lat": "34.6787013", "lon": "-77.5840059", "display_name": "West Main Street, lex, Troy Township, BIGG County, Ohio, 44333, United States", "class": "highway", "type": "primary", "importance": 0.6000099999999999 }, { "place_id": 329211743, "licence": "Data © OpenStreetMap contributors, ODbL 1.0. https://osm.org/copyright", "osm_type": "way", "osm_id": 38610646, "boundingbox": [ "34.6787122", "34.6871188", "-77.603118", "-77.5843465" ], "lat": "34.6827021", "lon": "-77.5937807", "display_name": "West Main Street, lex, Troy Township, BIGG County, Ohio, 44333, United States", "class": "highway", "type": "secondary", "importance": 0.6000099999999999 }, { "place_id": 329180475, "licence": "Data © OpenStreetMap contributors, ODbL 1.0. https://osm.org/copyright", "osm_type": "way", "osm_id": 823017968, "boundingbox": [ "34.9201281", "34.9214493", "-81.1346294", "-81.1251686" ], "lat": "34.9208004", "lon": "-81.1297602", "display_name": "West Main Street, Alliance, lex Township, Stark County, Ohio, 44601, United States", "class": "highway", "type": "tertiary", "importance": 0.6000099999999999 }, { "place_id": 329179580, "licence": "Data © OpenStreetMap contributors, ODbL 1.0. https://osm.org/copyright", "osm_type": "way", "osm_id": 19258266, "boundingbox": [ "34.9095347", "34.9189094", "-81.1539336", "-81.134635" ], "lat": "34.9146373", "lon": "-81.1445334", "display_name": "West Main Street, Alliance, lex Township, Stark County, Ohio, 44601, United States", "class": "highway", "type": "unclassified", "importance": 0.6000099999999999 } ]'; $data = json_decode($json, true); echo "latitude: {$data[0]['lat']} longitude: {$data[0]['lon']}"; Things to understand: json_decode can either create an array of php objects or a php array. Choosing array typically is simpler. Thus I passed true as the 2nd parameter to json_decode(). Javascript arrays (as they can now be represented in php as well) are enclosed in square brackets. [ ... this is an array of stuff ] The first structure in the array will array key 0 In this case your data is an array of javascript objects (the "name": value pairs) From there, all you need to do is reference the key value for the element you want. Therefore you get $data[0]['lat'] for the first array element 'lat' key from the original json object.
-
install the php8.2-xml extension
gizmola replied to rick645's topic in PHP Installation and Configuration
You don't need that package (php8.2-xml). XML support is already installed by default in the base 8.2 image. -
install the php8.2-xml extension
gizmola replied to rick645's topic in PHP Installation and Configuration
Did you try to remove those lines and if so, since they were redundant and problematic, what result did you have? You could also provide the Dockerfile you are using, which would allow others to recreate your experience. -
install the php8.2-xml extension
gizmola replied to rick645's topic in PHP Installation and Configuration
Install via apt should take care of installation of the extension, so I don't think you need these: && docker-php-ext-install php8.2-xml \ && docker-php-ext-enable php8.2-xml -
php form coding works on Safari but not on Firefox
gizmola replied to cearlp's topic in PHP Coding Help
Can you put your code in a code block in the future? Reading/looking at double spaced code without proper indentation or color syntax highlighting wastes everyone's time and effort and greatly decreases the final results. Notice @Moorcam helpful reply to you where he put an offending line into a proper block where the issue is easy to identify.