

kicken
-
Posts
4,705 -
Joined
-
Last visited
-
Days Won
179
Everything posted by kicken
-
Your example has missing cells, I assume they are supposed to be populated. Maybe something like this is what you're looking for: <?php $columns = [ range(1, 9), range(10, 19), range(20, 29), range(30, 39), range(40, 49), range(50, 59), range(60, 69), range(70, 79), range(80, 89), range(90, 99) ]; $number_of_cards = $_GET['cards'] ?? 6; $bingo_cards = []; while (count($bingo_cards) < $number_of_cards){ $card = []; foreach ($columns as $columnRange){ shuffle($columnRange); $card[] = array_slice($columnRange, 0, 3); } $hash = sha1(json_encode($card)); if (!isset($bingo_cards[$hash])){ $bingo_cards[$hash] = $card; } } foreach ($bingo_cards as $card){ echo '<table>'; for ($row = 0; $row < 3; $row++){ echo '<tr>'; for ($column = 0; $column < count($columns); $column++){ echo '<td>'.$card[$column][$row].'</td>'; } echo '</tr>'; } echo '</table>'; } For each card that is generated it goes through your $columns array and uses shuffle to randomize the order of the numbers. It then uses array_slice to pick off the first three numbers, one for each row. Finally it hashes the card and checks if that hash exists already to prevent duplicates. Keep in mind this only prevents duplicates for that one generation cycle. If you reload the page to generate more cards then there could be duplicates of the first batch in the second batch. If you want to prevent duplicates across all generation cycles you'll need to track the cards in a file or database. Finally it prints out a simple HTML table for each card.
-
When PHP initially saves the upload to the temporary folder with a random name (in the form of phpXXXX.tmp). Once the script ends, these files are then deleted. AFAIK PHP won't re-used the name of a file that already exists however so a file won't get overwritten while your trying to handle it. As far as when you generate a file random name to save the file permanently, re-use is something you need to consider. Something like what I showed above is unlikely to generate a duplicate name, however you can guard against it if you want by checking and generating a new one. do { $name = bin2hex(random_bytes(8)); } while (file_exists($name)); Technically even that is subject to a race condition, but the chance is so small I don't worry about it. Adding additional uniqueness on top of the random name will certainly help if that's something you want to do. For example you might use a format of $userName-$randomBytes so each user can have their own set of randomness. That would also allow you to reduce the number of random bytes. Creating a directory per user would similarly reduce the chance of conflict, and would also help prevent having tons of files in a single directory in case you ever need to inspect the directories manually. It basically just boils down to what you feel like implementing and how good is "good enough" for you. My go to these days is to have a simple table that associates files on disk with data in the database and using purely random names that are spread out by the first two letters of the name (ie f1d47394c0bf8d9d gets stored in f1/f1d47394c0bf8d9d).
-
PHP uploads the files into a temporary directory with a random name, so there's no problem. It's entirely up to you what happens after that. If you want to keep them around long term, you have to move them from that temporary directory to your own storage location. If you just do a simple copy/move to the same name then one or them will be lost. To be clear, you still store the files in a directory, not the DB. You just track what file you stored where using the DB. That allows you to mostly ignore the problem of clashing file names by either naming the file randomly or by using the auto-generated ID of the database record as the files name. It also enables you to store additional meta data about the file (who owns it, when it was uploaded, tags, # of downloads, etc) that can be used for additional features. Like I said, just do that then if you want $storageFolder = './Uploads/'; $nameTemplate = 'Content_%d.jpg'; $counter = getStartingNumber(); foreach ($uploadedFile as $file){ $diskName = bin2hex(random_bytes(8)); $friendlyName = sprintf($nameTemplate, $counter++); copy($file, $storageFolder.$diskName); // INSERT INTO user_file (UserId, DiskName, FriendlyName) VALUES ($userId, $diskName, $friendlyName) } Every user then would have their own Content_1.jpg ... Content_n.jpg without having to worry about file clashes. If you really don't want to use a DB, then the best thing to do would be to have a separate folder for each user, ie ./Uploads/$userId/ then you can still give each user their own Content_$number.jpg file in sequence. If you absolutely have to store everything in one directory then you need to have a lock file. Your script would obtain a lock on that lock file before processing the uploads. Then create your file using fopen($fileName, 'x'); to avoid any potential conflict and copy the data over.
-
 If you want to generate spreadsheets, look into updating to phpoffice/phpspreadsheet.
If you want to generate spreadsheets, look into updating to phpoffice/phpspreadsheet. -
@phppup, it doesn't matter how the files are stored on disk unless your users are just loading up that directory and viewing the files directly. Store them on disk however you want and just track which files belong to which user in your database then present them to the users that way. You can't really sequence them how you want unless you know ahead of time how many photos each user will be uploading. Say you decide to just +10 for each user so Linda is 1-10, You're 11-20 and Ricky is 21-30. So everyone uploads one photo and now you have Concert_1.jpg, Concert_11.jpg, Concert_21.jpg like you want. But then Linda uploads 20 photos not 10? You have a problem, your files are no longer grouped nicely. Forgot about trying to match the physical storage to some sort of order like that. Just store them. Handle the sorting/ordering in the DB.
-
That's what the selectors are for (the .container, .divL, .divR etc). Where you put the code in your CSS file probably doesn't matter unless you have multiple selectors trying to override each other or specificity issues. Just put your stuff at the end of the CSS file and see if there's a problem. If there is, then you may need to either adjust where you put it or adjust your selector specificity.
-
Using a DB allows you to store meta-data separately from the physical file, so the name you actually give the physical file become irrelevant. In my systems all the files are stored with an random name, generated using something like bin2hex(random_bytes(8)); which results in a name like f1d47394c0bf8d9d. That is the name of the file on disk and means there is very little chance of a name collision (though I check anyway for one). That random name is then stored in the database along side whatever the name of the original upload was ($_FILES['blah']['name']) and the original mime type ($_FILES['blah']['type']) so when the user wants to view their files I can show it in their original name and download it with the original type. As a result every user can have their own me.jpg or whatever without any conflicts on the server. If you'd rather have your own naming convention rather than preserving the user's original name then all you do is generate and save your custom name rather than the original, everything else is the same.
-
Keep in mind that if your web server is a different computer than the one your browsing on, you need to install the CA on the computer your browsing on, not the web server. The same may be true if it's the same computer but different user accounts.
-
The type of data your processing and how you are loading that data can make a huge impact on the runtime of your scripts. For example if you're querying a database you might be running hundreds or thousands of queries when instead you could run one or two. You might be looping over your result set many times to apply different actions when maybe a little refactoring could do the same in one or two loops. 30 seconds is a long time so either your processing a large amount of data or your code is very inefficient. Breaking up the task across ajax calls may be possible, but you should make sure your PHP code is as efficient as it can be first.
-
Trying to compress and make my code faster
kicken replied to mongoose00318's topic in PHP Coding Help
in_array checks the array values, not the keys. To check if a key exists you can use isset or array_key_exists. if (isset($statuses[75352])){ echo 'TRUE'; } -
Trying to compress and make my code faster
kicken replied to mongoose00318's topic in PHP Coding Help
They can be NULL in that case because of the LEFT JOIN. The join condition includes p2.submit_time > p1.submit_time, that means for each row in p1 it will attempt to find a row in p2 where p2's submit_time is greater than p1's submit_time (in addition to the other conditions). If it can't find any row that matches, the all the p2 columns will be null. So, since whatever the most recent entry in p1 is won't be able to find a matching row in p2, p2.id will be null and filtering on that condition in the where clause results in you only receiving the most recent rows from p1. -
The documentation shows that there is an open method for the date picker, so just add a click handler for your icon that will call that open method. <i class="material-icons prefix datepicker-trigger">calendar_today</i> <input type="text" name="r_date" class="datepicker"> $('.datepicker').datepicker({format: 'yyyy-mm-dd'}); $('.datepicker-trigger').click(function(){ $(this).next('.datepicker').datepicker('open'); });
-
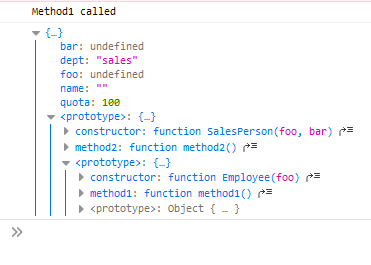
Just adding it to the prototype means every instance of the object will share the same instance of the function. Given code like this: function Employee(foo) { this.foo = foo; this.name = ''; this.dept = 'general'; } Employee.prototype.method1 = function(){ console.log('Method1 called'); }; function SalesPerson(foo, bar) { Employee.call(this, foo); this.bar = bar; this.dept = 'sales'; this.quota = 100; } SalesPerson.prototype = Object.create(Employee.prototype); SalesPerson.prototype.constructor = SalesPerson; SalesPerson.prototype.method2=function() { console.log('Method 2 called'); } When you this: var p = new SalesPerson(); p.method1(); Javascript looks up method1 by roughly doing: Does p have a property named method1? => No Does SalesPerson.prototype have a property named method1? => No Does SalesPerson.prototype.prototype (Which is Employee.prototype) have a property named method1? => Yes Execute SalesPerson.prototype.prototype.method1.call(p); So only one instance of the method1 function exists on the Employee.prototype object, it's just reused for the other objects. You can see this kind of chain if you console.log(p): If you want to share a single function across multiple objects that are not related via their prototype chain, then you'd do define your function elsewhere and assign a reference to it to each object. This kind of setup is often called a mixin. For example if you had some logging code you wanted to include in each class. var LoggerInterface = { log: function(msg){ console.log(msg); } }; function Employee(foo) { this.foo = foo; this.name = ''; this.dept = 'general'; } Object.assign(Employee.prototype, LoggerInterface); Employee.prototype.method1 = function(){ this.log('Method1 called'); }; function Equipment(){ this.name = ''; } Object.assign(Equipment.prototype, LoggerInterface); Equipment.prototype.method2 = function(){ this.log('Method2 called'); } Both Employee and Equipment would have their own independent .log properties, but they would both reference the same underlying function so the function itself isn't duplicated.
-
One reason people would define methods in the constructor rather than on the prototype is to simulate private properties. In Javascript all properties are public so anything you attach to an object could be manipulated by other code. To work around that people would keep these "private properties" as regular variables inside the constructor rather than as actual properties on the object. In order to do that and still access them from the methods, the methods need to be defined in the constructor so they can access the constructors variable scope. function Counter(){ var count = 0; this.increment = function(){ count++; }; this.decrement = function(){ count--; }; this.current = function(){ return count; }; } As mentioned, one downside to this is that each instance of the object ends up with it's own instance of the function rather than a single instance being shared. On modern desktops with lots of memory that's probably not an issue unless your creating many thousands of instances of the object. However on older systems or mobile systems with less memory it can cause issues much faster.
-
The rationale is that even though they are deprecated, they are technically still available to be used and someone may want/need to use them. I've used various libraries in the past that have created a new API and deprecated their old one. Usually updating to the new API isn't something that can be done right away so when I need to work on that code I'll need to continue to use those deprecated functions for a while. Not sure about VSCode but PHPStorm shows such functions with a strike-out in the autocomplete popup as well so you know right away that the function is deprecated. That lets you easily avoid them in new code but still have access to them when maintaining existing code.
-
Defining a value in the parameter list makes that parameter optional. If it's not provided when the function is called, the it takes on the value assigned to it. Your specific example doesn't really make use of the feature effectively. Take something like this for example though: function findFiles($directory, $includeHidden = false){ $iter = new DirectoryIterator($directory); $list = []; foreach ($iter as $item){ if ($item->isFile()){ $isHidden = $item->getFilename()[0] === '.'; if ($includeHidden || !$isHidden){ $list[] = $item->getPathname(); } } } return $list; } That function requires at least one parameter when it's called, the directory to search. So you end up with the following options for calling it $files = findFiles('/home/kicken'); /* executes with $directory = '/home/kicken', $includeHidden = false */ $files = findFiles('/home/aoeex', true); /* executes with $directory = '/home/aoeex', $includeHidden = true */
-
Because you aliased it from grade to pgrade.
-
You need to select the columns in your inner query. Alias them if needed. Then in the outer query is where you use them. mostRecent is the name assigned to the results of the inner query so it is only valid in the outer query and you use it to reference whichever columns you select.
-
You need have whatever columns you want to order by in the outer query as part of the select clause of the inner query. If you check my original query you'll see I added the grade and nameLast columns to the select list. If you alias them, then use the alias in the order by clause of the outer query.
-
Get rid of the * in your select.
-
And I told you: The aliases are only for your SELECT and the outer query. Continue using the table.column name syntax in your conditions and joins.
-
Yes, that's the point. It loops endlessly as a service checking for work to do. When it finds some, it does it. Otherwise it just sleeps, checking each second for new work. You can adjust the sleep period based on what your requirements are, or implement some method so it sleeps until specifically triggered to check for work (ie, through a socket).
-
The code I posted needs to have aliases added to it as you discovered. If after adding those you're still having issues then you need to post the code you are using after you've applied your modifications.
-
Is there a reason you're running it as a separate task in the first place? Most of the time this is done because the work can be time consuming and you don't want the user to have to wait and trying to accomplish that with on-demand task launching can be problematic in PHP in my experience. The best way to accomplish that kind of separation is to simply keep the scripts separate entirely using either a scheduled task or service for one half. There's generally nothing wrong with setting up a job to just run every minute (or whatever you require) to check for work. If there is some, do it. If there isn't, exit. It might feel wasteful to run a script over and over with nothing to do but it's really not an issue and doesn't need to be avoided. The downside to a scheduled task is you can only run it once a minute, if you need faster response times than a minute then you move to a service and either check for work more frequently or communicate with the service via a socket or a job server/queue server (gearman, redis, beanstalked, memcached, etc). For example, I have an application that allows admins to import user accounts from LDAP. The process can take a bit for large imports so similar to you I just INSERT a record into an ldap_import_request table from my web app. On the server I use nssm to run a PHP script as a service and that script essentially runs a loop looking for new records. while (true){ $pendingRequests = loadPendingImportRequests(); foreach ($pendingRequests as $request){ processImportRequest($request); } sleep(1); //Avoid eating up CPU when idle. } You can get more advanced if you want, but I find this simple loop/table setup is fairly effective.
-
Dont launch your second script from the first. Set it up as a system service (using nssm) or as a scheduled task.

