

kicken
-
Posts
4,705 -
Joined
-
Last visited
-
Days Won
179
Everything posted by kicken
-
That link is relative to the current URL. So if you're say on https://example.com/client1/menu, clicking that link will attempt to load https://example.com/client1/menu/client1/gallery When you're rewriting your URLs you need to take into account your URLs may not match up with what your filesystem looks like and make sure you link accordingly. In general it's almost always best to link things in a domain relative fashion, with a leading /. <a href="/client1/gallery/2019-holiday-party">2019 Holiday Party</a> Also, in case you're still not clear on the [R] issue: A normal RewriteRule without the [R] tells Apache "Hey buddy, I know the client asked for X but let's really give them Y instead, don't tell them about it though." If you add the [R], that changes the hypothetical conversation to "Hey buddy, I know the client asked for X but they really want to ask for Y. Can you please let them know they need to request Y instead?" By adding the 301 into the mix ([R=301]), your modifying the conversation even further to say "Hey buddy, I know the client asked for X but they really want to ask for Y. Can you please let them know they need to request Y instead and that this will always be the case and they should never request X again?" Browsers may cache such 301 redirects so that if you attempt to visit the original URL again the browser itself will re-write to the redirected URL before even making the request. As such, if you make such a redirect by mistake (as you were) it's not easily fixed. Sometimes closing the browser entirely (not just the tab/window) will clear those redirects, other times you may have to clear the browsers cache to remove them.
-
RewriteCond %{REQUEST_FILENAME} !-d Ensures the request does not map to a valid directory. RewriteCond %{REQUEST_FILENAME} !-f Ensures the request does not map to a valid file RewriteCond %{REQUEST_FILENAME}.php -f Ensures that if you add .php to the requested location, it does map to a valid file. RewriteRule .* $0.php [L] If all the above conditions are true, then this matches the entire URL (the .*) and rewrites it to include the .php suffix. The parentheses create a group which can be referenced in the substitution. In this instance they are not needed because you want to refer to the entire match which is already handled by $0 which is an automatic reference to the matching input string as a whole. If you wanted to match only a subset of the input string, then you'd use parentheses and $1, $2, etc.
-
The point of explicitly checking for false is usually to avoid confusion. For example if there were a file named "0" then the loop would incorrectly stop at that file.
-
Then get rid of them and see if anything changes. Have you seen this with any registration or just ones you're trying to do as a test? Have you tried different email clients? Maybe you have something running that's scanning your incoming email and following links.
-
 It's not something you can set in your php.ini file, it's an apache directive not a PHP directive. Custom apache configurations are generally handled via a .htaccess file but only some directives are allowed in that file and as far as I know, this is not one of them. Godaddy would have to modify the vhost configuration for your site on their end to enable their directive and I doubt they would bother with that. Like I said before also, there is really not much point in enabling it. Essentially it just causes apache to do exactly the same thing as what you did in your original post, a DNS lookup on the REMOTE_ADDR. So if you really wanted to, you could just do it yourself via: $_SERVER['REMOTE_HOST'] = gethostbyaddr($_SERVER['REMOTE_ADDR']);
It's not something you can set in your php.ini file, it's an apache directive not a PHP directive. Custom apache configurations are generally handled via a .htaccess file but only some directives are allowed in that file and as far as I know, this is not one of them. Godaddy would have to modify the vhost configuration for your site on their end to enable their directive and I doubt they would bother with that. Like I said before also, there is really not much point in enabling it. Essentially it just causes apache to do exactly the same thing as what you did in your original post, a DNS lookup on the REMOTE_ADDR. So if you really wanted to, you could just do it yourself via: $_SERVER['REMOTE_HOST'] = gethostbyaddr($_SERVER['REMOTE_ADDR']); -
strategies to prevent spamming out of PHP emails
kicken replied to ajetrumpet's topic in PHP Coding Help
Your SPF record needs to include the IP address of the server that is sending the email. From your post it's not clear if that's what you did or not. Also, if your using some hosting provider such as godaddy, they may have several servers handling mail so you need to either include all their IP's or defer to them. From what I can put together by skimming "What are the correct GoDaddy SPF Settings?" your SPF entry in DNS should probably look something like: v=spf1 include:secureserver.net ~all If you send email from other sources besides godaddy, you'll need to add those sources to the SPF record as well. Beyond that, do look into using either PHPMailer or Swiftmailer instead. They will make it easier for you to ensure that messages contain all the proper headers and are formatted correctly. -
If you did, they may not even enable it for you. Doing a reverse-dns lookup on every request can cause quite the performance bottleneck and eat up bandwidth unnecessarily. There's really not that much useful information to be gained from a reverse lookup in most cases so it's a bit pointless to even bother. For most people surfing the web, a reverse lookup with either a) fail and return no results or b) return some auto-generated host name that probably won't give you much more info than who there ISP is (if even that).
-
Are you trying to get the cURL resource so you can call various curl_* functions using it?
-
You can't really. JSON is more or less an all-or-nothing encoding type, it can't easily be broken up into chunks. If you don't need the JSON conversion and can just parse through it yourself for the data you need, you could use the read method on the body to receive the response piece by piece and look for the information you need. You'd have to spend a fair bit of time essentially writing your own json parser which is less than ideal IMO. Unless there's some reason not too, the best solution is to just increase your memory limit.
-
Because you're not concatenating the function call like I showed, your just embedding it in the string and it doesn't work like that. The proper way is to end the string and concatenate, like so: $param_1 = "AND projects.min_price >= " . Parameterized($url_min_price, $binds); $param_2 = "AND projects.max_price <= " . Parameterized($url_max_price, $binds); $param_3 = "AND projects.featured = " . Parameterized($url_featured, $binds); As Barand mentioned though, there are other issues with that version of the code. $where[] = 'MATCH(title) AGAINST(? IN BOOLEAN MODE)'; $binds[] = $search_query;
-
I have a function that I use so that you can still code like old school concatenation, but use modern binding. It goes a little something like this: function Parameterize($value, &$binds){ static $counter = 0; if (!is_array($binds)){ $binds = []; } if (is_array($value)){ if (count($value) == 0){ return 'null'; } else { $allParams = []; foreach ($value as $v){ $allParams[] = Parameterize($v, $binds); } return implode(',', $allParams); } } else { if (is_bool($value)){ $value = (int)$value; } else if ($value instanceof \DateTime){ $value = $value->format('Y-m-d H:i:s'); } $param = ':param' . (++$counter); $binds[$param] = $value; return $param; } } You'd then use it like: $min_price = 10; $max_price = 50; $featured = 1; $binds = []; $sql = ' SELECT * FROM projects WHERE min_price >= '.Parameterize($min_price, $binds).' AND max_price <= '.Parameterize($max_price, $binds).' AND featured = '.Parameterize($featured, $binds).' '; $find_records = $db->prepare($sql); $find_records->execute($binds); $result_records = $find_records->fetchAll(PDO::FETCH_ASSOC); I find it keeps things easy to understand and helps reduce the code footprint while still keeping things safe.
-
identifying web crawlers / spiders by ip address
kicken replied to ajetrumpet's topic in PHP Coding Help
Friendly spiders such as google's will identify them via the User-Agent header in their HTTP requests. For example, google sends: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) This header is most likely how the forum is deciding if it's google or not. If you follow that link in the user agent header for google, they mention being able to verify an IP belongs to google bot by doing a reverse DNS lookup on it. Other spiders may or may not have a similar IP verification mechanism, you'd have to research them individually. -
Implications of entity one-to-one relationships
kicken replied to NotionCommotion's topic in PHP Coding Help
In general I'd say your common object should only contain the common properties. As such, your common object shouldn't contain any references to some other item-specific details. The reference to the common object should either be in the specific details or some linking table. Another way to look at it is, if your relationship wasn't one:one then you'd have to reference the common object from inside the specific object. Since in the one:one you could technically do it either way, might as well do it the same way in both cases for a) Consistency and b) Makes a one:one to one:many conversion later easier. So from what I understand of your gateway/devices situation, you'd end up with something like this: PhysicalDevice represents your Modbus/Bacnet/whatever devices that are pre-generated. These rows are essentially static and never changed. Then you have your Datasource, gateway, device one-to-one relationships connecting those all together. If your device needs to be using one of the physical devices you set PhysicalDeviceId, otherwise leave it null. Or if needed, break out the physical device mapping to yet another table. If you need to determine which physical devices are being used, just check if there is any reference to them in the Device table. Not sure if any of that will help with your real situation or not.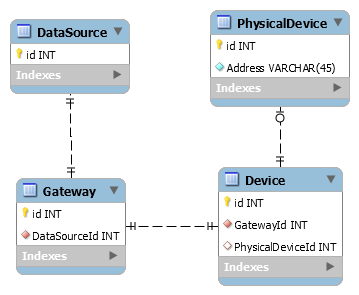
-
Implications of entity one-to-one relationships
kicken replied to NotionCommotion's topic in PHP Coding Help
I'm not too sure what your going for with your gateways, devices, etc. If you haven't yet reached a conclusion to your problem, I'd suggest trying to refine the details on that some. As I understand it you have some AbstractDataSource type which is responsible for gathering data from somewhere and GatewayDataSource is a specific type of source. GatewayDataSource uses some sort of AbstractGateway to obtain that data (different specific gateway types exist). So it would seem at this point you have essentially - AbstractDataSource/GatewayDataSource: Requires a gateway instance so a foreign key is needed. You're unsure whether the foreign key should exist in the AbstractDataSource or AbstractGateway tables. - AbstractGateway: Might use a device so it should have a (NULLable?) foreign key to a specific device. You're unsure whether the foreign key should exist in the AbstractGateway or Device tables. - Device: Standalone object It sounds to me currently like your gateway and device object might be setup to be shared instances that different data sources just link to. If that's the case, then keep the references in the data source. Have your source link to both the gateway and device and composite them together as needed. If every data source gets it's own unique gateway, then you could instead link the source to the gateway then link the gateway to the device. This is the part of your post that is causing me issues trying to understand what kind of setup you have and thus how it should be structured. This implies to me your devices (and maybe gateways) are some kind of shared resource meaning many gateways may link to the same device so if a gateway is deleted it shouldn't be deleting the device as it might still be used by others (now or later). It might be helpful for explaining the situation to focus more on explaining how the physical networks your trying interact with work and what you need to do with them, rather than or in addition to the code your trying to write. On a side note to the evolved car/motor example (which doesn't seem like the same situation to me), in the past I've essentially made two relationships for such situations. 1) Car has some sort of CurrentMotorId foreign key that would reference whichever motor is currently being used by the car 2) Every motor has a CarId foreign key reference to indicate which car that motor was used in (either in the motor table or a linking table if motors are shared between different cars over time) Current car operation can be handled using the first relationship. Historical service data can be found using the second relationship. -
If everything is working for you, then great, run with it. However, I'm curious if there's a particular reason you cant just add/remove your network_node entries as needed? You say every account has a specific number of them. That seems like a requirement best handled at the software level where these records are managed. In the database you'd just have nodes that are actually in use, but in the management UI you could display X number of nodes for the account at all times. If the user adds a network to the node, insert a new network_node. If they remove the network, delete the node.
-
Return from ajax results in object being undefined
kicken replied to ajoo's topic in Javascript Help
Your code block is messy and doesn't make a lot of sense. For example, what is playServerURL()? Is that supposed to be where your ajax call is? Then why isn't it? What are those three lines of dots that are absolutely a syntax error? You need to post something more representative of what you have, not just random lines that show no structure and won't even compile. That said, you don't return data from an ajax call by using return because of the deferred nature of the ajax process. Either you use a callback function that then accepts the data (like how $.ajax calls your success handler) or you return a promise that can then have callbacks added to it and are run when the data is ready. -
In PhpStorm to support PSR-2 rules
kicken replied to mstdmstd's topic in PHP Installation and Configuration
For PHP you can go to Settings -> Editor -> Code Style -> PHP and on the right there is a Set from... link. Click it and choose Predefined Style -> PSR1/PSR2 That'll give you a basic setup which you could tweak as desired. While your editing a file you can press CTRL+ALT+L to have it re-format the document according to your style settings. -
Loading and playing sounds dynamically off the server.
kicken replied to ajoo's topic in Javascript Help
Your problem is probably just that in javascript strings are not suitable for binary data. Javascript will convert the response to UTF-16 which will end up corrupting your MP3 data. You need to process the response as a binary blob instead of a string. -
@TinLy, Unless your client has direct access to your database some how, presumably they are changing it by making a request to some script you have on the server and sending it information. If that's true then you can simply "do something" at that point rather than having to constantly poll your database. Otherwise, stick with polling if you want but limit your query rate to something acceptable which might mean the detection of said change may be delayed a bit. For example, maybe wait a minute etween checks, or 5 minutes if that's still too much. You're being too vague about your situation to really provide any better help. If you need more help you'll have to start getting into specifics instead of just saying "something changed", "do something", "client", etc.
-
Not really no. If you want to know the content of your database you have to query for it. If you explain more about what your goal is then perhaps there is an alternate solution. For example, maybe you should just "do something" in the same place that you change your database, then you won't have to query it constantly to detect a change.
-
Converting collection of objects to JSON
kicken replied to NotionCommotion's topic in PHP Coding Help
It is, but the idea is that you could use that to guide your serialization. You'd create a schema that describes the end result of the JSON output you need. That schema would then end up list the objects and properties that make up that json output. You could then write a class that reads that data from the schema and finds those properties on the objects you pass it to generate the JSON output. When I was looking into a while back it that was essentially what I was thinking of doing. I had an API that accepted and responded with JSON. I was going to define a schema for each endpoint to validate that POST'ed json data was valid. The idea was to then also serialize responses by using the schema. I never got that far with it though as things changed. You don't have to do it within your entity. I wouldn't say there's anything wrong with it in this case though. The part of the code that is part of your entity would just be returning the data that should be serialized. The actual serialization process would still be in a separate service class. Like most things it's a trade off between what gets the job done what what might be an ideal solution. The ideal solution might involve a number of classes and mapping files to configure what data to pull from what objects. That'd take time to design an implement though. A service that just asks the entity directly for the data would be simpler and easier to implement, but maybe less flexible and muddies up the entities a bit. I find a lot of the times it's better to start with the less ideal solution that works so you can get a better understanding of what you actually need to do (vs what you think you'll need to do) then you can re-factor that into a better solution later on. -
Converting collection of objects to JSON
kicken replied to NotionCommotion's topic in PHP Coding Help
I don't understand why you have your $bDiffName and getBDiffName() instead of just overriding getB(). If both properties serialize as 'b' I don't see the point in separating them. If the JSON Schema doesn't work for you that's fine. What you could do is just define your own JsonSerilzable like interface that your entities implement. You could either have separate methods to create your different representations or one method that you pass some parameters too in order to determine the proper serialization. -
Converting collection of objects to JSON
kicken replied to NotionCommotion's topic in PHP Coding Help
If you need different views for the same object then I'd suggest creating a separate service that handles that. Pass it the object(s) you want to serialize and the type of view you want and let it handle the serialization rather than the entity with JsonSerializable. For example, maybe write a class that takes an object and a JSON Schema and will serialize the object according to that schema. Then you can just create a different schema for each data view you need. I looked into doing something like this once, but ended up going a different direction that made it not necessary. -
A form field is a form field, whether it's hidden or not is irrelevant. Your user has control over it's value so you always have to validate the data. So long as you do that and take proper precautions such as prepared statements for any queries using those values you're fine. Just don't ever assume that because it's hidden the value can be trusted. Ie, don't do something like <td> <form id="offer01" action="" method="post"> <input name="planID" type="hidden" value="mp-1111"> <input name="planPrice" type="hidden" value="20"> <input name="planSelected" type="submit" value="Select"> </form> </td> And assume that someone can't change the price field because it's hidden.
-
If you're developing them as essentially separate sites I'd probably give them separate repositories as well. I'd also use separate domains such as www.example.com and admin.example.com, which would then end up being separate folders on disk such as /var/www/www.example.com/ and /var/www/admin.example.com/ Whatever works best for you and makes sense is probably fine though. I'm currently working on an API for an existing site. Like you the API and the site share the same database but are separate things more or less. The API has it's own git repository and is stored on a separate folder on the server. Since I don't control to domain it'll end up just being a sub-folder of the current site via an Alias /api /var/www/example-api in the server configuration.

