

Barand
-
Posts
24,615 -
Joined
-
Last visited
-
Days Won
835
Everything posted by Barand
-
inet_aton and inet6_aton not working on local server
Barand replied to larry29936's topic in MySQL Help
I know. If only someone would invent JOINs. -
inet_aton and inet6_aton not working on local server
Barand replied to larry29936's topic in MySQL Help
Are ip_start and ip_end columns the string values or are they varbinary(16)? -
inet_aton and inet6_aton not working on local server
Barand replied to larry29936's topic in MySQL Help
That should work OK Try sorting the data on address. Any weird values might go to either the top or the end and make them easy to find. At what point do you use inet6_aton()? -
inet_aton and inet6_aton not working on local server
Barand replied to larry29936's topic in MySQL Help
Tried to replicate the error message myself ... My table CREATE TABLE `download` ( `download_id` int(11) NOT NULL AUTO_INCREMENT, `ip_address` varbinary(16) DEFAULT NULL, `address` varchar(50) DEFAULT NULL, PRIMARY KEY (`download_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; My csv data ip_address,address "","255.50.1.123" "","255.50.11.123" "","255.50.2.123" "","255.50.4.123" Running the csv upload query, but omitting the IGNORE to skip the header line) LOAD DATA LOCAL INFILE 'c:/inetpub/wwwroot/test/ip_test.csv' INTO TABLE download FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' -- IGNORE 1 LINES (ip_address, address) SET ip_address = inet6_aton(address); Gave the message And this in the table SELECT download_id , HEX(ip_address) as binaryIP , address as stringIP FROM download; +-------------+----------+---------------+ | download_id | binaryIP | stringIP | +-------------+----------+---------------+ | 1 | NULL | address | | 2 | FF32017B | 255.50.1.123 | | 3 | FF320B7B | 255.50.11.123 | | 4 | FF32027B | 255.50.2.123 | | 5 | FF32047B | 255.50.4.123 | +-------------+----------+---------------+ EDIT: Also, specifying the wrong line terminator character (eg /n instead of \n) gave the same 1411 warning and the records in the table were like this +-------------+----------+----------------------------------------------------+ | download_id | binaryIP | stringIP | +-------------+----------+----------------------------------------------------+ | 8 | NULL | address"" | | 9 | NULL | "255.50.1.123"","255.50.11.123"","255.50.2.123" | +-------------+----------+----------------------------------------------------+ -
That is setting the value to 3, not testing if it is equal to 3. The equality operator is "=="
- 1 reply
-
- 1
-

-
Another approach would be to have a table in which you record users' logins. CREATE TABLE `user_login` ( `login_id` int(11) NOT NULL AUTO_INCREMENT, `user_id` int(11) DEFAULT NULL, `login_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`login_id`), KEY `idx_user_login_user_id` (`user_id`) ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8; To get the last login you query the table for the latest time. For example, suppose the table contains +----------+---------+---------------------+ | login_id | user_id | login_time | +----------+---------+---------------------+ | 1 | 1 | 2020-05-08 10:31:20 | | 2 | 2 | 2020-05-09 14:54:11 | | 3 | 1 | 2020-05-09 14:55:39 | +----------+---------+---------------------+ then, for user #1 SELECT COALESCE(MAX(login_time), 'Data unavailable') as last_login FROM user_login WHERE user_id = 1; +---------------------+ | last_login | +---------------------+ | 2020-05-09 14:55:39 | +---------------------+ but for user #3 SELECT COALESCE(MAX(login_time), 'Data unavailable') as last_login FROM user_login WHERE user_id = 3; +------------------+ | last_login | +------------------+ | Data unavailable | +------------------+ After getting the last login, write the new login (the login time will be inserted automatically) INSERT INTO user_login (user_id) VALUES ( ? );
-
I don't think you need bother with the json. Just define your table as something like this CREATE TABLE `bookmark` ( `bookmark_id` int(11) NOT NULL AUTO_INCREMENT, `user_id` int(11) DEFAULT NULL, `page_link` varchar(50) DEFAULT NULL, `css_icon` varchar(50) DEFAULT NULL, `icon_photo_link` varchar(50) DEFAULT NULL, `language` varchar(10) DEFAULT NULL, `icon_title` varchar(50) DEFAULT NULL, PRIMARY KEY (`bookmark_id`), UNIQUE KEY `unq_page_link` (`page_link`), KEY `idx_user` (`user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-
I stopped reading earlier when I spotted the quotes. Then I read the rest of the line. That syntax is completely wrong. You were almost there with the prepared statement that you apparently abandoned. A pity because that is the correct method, you should not be putting variable directly into the sql. Omit id from the column list and the corresponding null in the values (that will happen anyway) Your bind_param is missing the variable types eg ('ssss')
-
Don't put column names in single quotes.
-
No. One table named "bookmark" and store the user's id in each bookmark record. If your site currently uses a database, just put the extra table in that. You can check how many each user has with a simple SELECT COUNT(*) as total FROM bookmark WHERE userid = ?; How that is stored depends on what those "necessary values" are. If the arrays always contains the same keys I'd create a column in the bookmark table for each key. If the keys vary from bookmark to bookmark then store as a json encoded array (MySQL 5.7+ supports json columns) If "bookmark_title" should be unique, enforce it in the table by placing a UNIQUE constraint on that column.
-
Store part of array when array_search is successful
Barand replied to mongoose00318's topic in PHP Coding Help
That isn't the most comprehensive requirements specification that I have worked from so there is a bit of guesswork involved, such as the comparison criteria being job number and line item matching, and which columns are to be updated from the csv data. If this is the case, your "production_data" table should have an index on these columns (as my temp table below has). Anyway, given those caveats, the processing would be along the lines below (4 queries instead of 40,000) and should give you a guide. <?php ## ## This initial section would normally be in an included file ## const HOST = 'localhost'; const USERNAME = '???'; const PASSWORD = '???'; const DATABASE = '???'; function pdoConnect($dbname=DATABASE) { $db = new PDO("mysql:host=".HOST.";dbname=$dbname;charset=utf8",USERNAME,PASSWORD); $db->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); $db->setAttribute(PDO::ATTR_DEFAULT_FETCH_MODE, PDO::FETCH_ASSOC); $db->setAttribute(PDO::ATTR_EMULATE_PREPARES, false); $db->setAttribute(PDO::MYSQL_ATTR_LOCAL_INFILE, true); return $db; } ## ## Connect to DB server ## $db = pdoConnect(); ## ## create a temporary table to store the csv data ## $db->exec("CREATE TEMPORARY TABLE production_csv ( id int not null auto_increment primary key, enterprise tinytext, part_num text, description text, qty int, line_item varchar(11), job_num int, work_order varchar(50), psm varchar(50), date_change_flag tinyint, scheduled_ship_date date, on_hold tinyint, on_hold_reason varchar(50), total_hours decimal(10,2), worfc varchar(50), INDEX job_line (job_num, line_item) )"); ## ## load the csv data into the table ## $db->exec("LOAD DATA LOCAL INFILE 'prod_data.csv' INTO TABLE production_csv FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' IGNORE 1 LINES (@dummy, @dummy, enterprise, part_num, desc, qty, line_item, job_num, work_order, psm, date_change_flag, scheduled_ship_date, on_hold, on_hold_reason, total_hours, worfc) "); ## ## write matching production_data records to archive ## $db->exec("INSERT INTO production_archive SELECT pd.* FROM production_data pd JOIN production_csv USING (job_num, line_item) "); ## ## update the production_data table from the production_csv table ## $db->exec("UPDATE production_data d JOIN production_csv c USING (job_num, line_item) SET d.enterprise = c.enterprise, d.part_number = c.part_num, d.description = c.description, d.qty = c.qty, d.as400_ship_date = c.scheduled_ship_date, d.hold_status = c.on_hold ") ?> -
Store part of array when array_search is successful
Barand replied to mongoose00318's topic in PHP Coding Help
Show us the table structure/s you are working with and the csv layout. Tell us precisely what the goal is and let's see if we can come up with a more efficient way than 40,000 queries. -
Store part of array when array_search is successful
Barand replied to mongoose00318's topic in PHP Coding Help
Databases were designed for matching and searching. Any particular reason why you pull data from the DB then do the searching? That is not the way to use key() array_search returns the key of the found item, not a count. -
I'd do something like this $data = json_decode($j, 1); foreach ($data['results'][0]['address_components'] as $address) { if (in_array('sublocality', $address['types'])) { echo "Sublocality : {$address['long_name']}<br>"; } if (in_array('administrative_area_level_1', $address['types'])) { echo "Administrative area level 1 : {$address['long_name']}<br>"; } }
-
Here's one way <?php $n = 1; for ($i=0; $i<12; $i++) { printf("%15d | %-20s\n", $n, weird_format($n)); $n *= 10; } function weird_format($n) { if (($k = strlen($n)) < 4) return $n; $a = substr($n, 0, $k-3); // split off the last 3 chara $b = substr($n, -3); if (!($k%2)) $a = ' '.$a; // ensure first section is even no of chars $c = str_split($a, 2); // split into groups of 2 return trim(join(',', $c) . ',' . $b); // join them with commas } ?> Output: 1 | 1 10 | 10 100 | 100 1000 | 1,000 10000 | 10,000 100000 | 1,00,000 1000000 | 10,00,000 10000000 | 1,00,00,000 100000000 | 10,00,00,000 1000000000 | 1,00,00,00,000 10000000000 | 10,00,00,00,000 100000000000 | 1,00,00,00,00,000
-
First, tell mysqli to throw exceptions on errors mysqli_report(MYSQLI_REPORT_ERROR|MYSQLI_REPORT_STRICT); then try{} it.
-
VARBINARY (16) would give you a common type for IPv4 and IPv6
-
According to my manual...
-
Calculating Inbreeding on a 10 Generation Pedigree
Barand replied to Triple_Deuce's topic in PHP Coding Help
@Beluga Don't attribute things to me that I didn't say. Don't hijack other people's threads Don't resurrect old topics. -
mysql> CREATE TABLE `download` ( -> `download_id` int(11) NOT NULL AUTO_INCREMENT, -> `ip_address` varchar(50) DEFAULT NULL, -> `address` varchar(50) DEFAULT NULL, -> PRIMARY KEY (`download_id`) -> ); mysql> INSERT INTO download (address) VALUES ('66.249.75.215'); mysql> UPDATE `download` SET `ip_address` = hex(inet_aton(`ADDRESS`)) WHERE ip_address is null; mysql> SELECT address -> , ip_address -> FROM download; +---------------+------------+ | address | ip_address | +---------------+------------+ | 66.249.75.215 | 42F94BD7 | +---------------+------------+
-
I'd expect 1 & 4
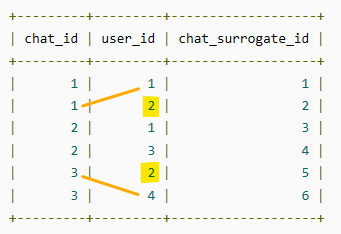
-
... WHERE b.user_id = 1 AND a.user_id <> b.user_id; -- ADD THE CONDITION
-
mysql> CREATE TABLE `download` ( -> `download_id` int(11) NOT NULL AUTO_INCREMENT, -> `ip_address` int(10) unsigned DEFAULT NULL, -> `address` varchar(50) DEFAULT NULL, -> PRIMARY KEY (`download_id`) -> ); mysql> INSERT INTO download (address) VALUES ('66.249.75.215'); mysql> UPDATE `download` SET `ip_address` = inet_aton(`ADDRESS`) WHERE ip_address is null; mysql> SELECT address -> , HEX(ip_address) as ip_address -> FROM download; +---------------+------------+ | address | ip_address | +---------------+------------+ | 66.249.75.215 | 42F94BD7 | +---------------+------------+
-
Of course it does - as already stated, inet_aton() is an SQL function not PHP
-
$stmt = $pdo->prepare("UPDATE `download` SET `ip_address` = inet_aton(`ADDRESS`) WHERE ip_address is null;"); @gw1500se Those look like backticks to me
